——"一片向日葵花海在星空下閃爍。"
本來只是在有限的想像力之內挑了梵高的兩幅名畫加以簡單概括,結果AI吞掉這句描述後,居然就吐出了一張張極富衝擊力的圖像:

圖源:Simon_阿文微博
沒有參考圖像,也並非簡單的兩幅圖像的拼接融合,而是真正基於文字描述,在充分的想像力下,從無到有地進行了繪畫創作。
而就在不到一年的時間內,這樣的AI畫手開始井噴式地出現——
近期在海內外爆火的免費AI作畫工具Disco Diffusion,輸入簡單的文字描述就能在線生成圖像,其畫面之精細,想像力之超絕讓不少人直呼「AI比我都浪漫」:

圖源:開發者推特
一度登上蘋果應用商店的圖形與設計排行榜榜首的Wombo,只要下載App,上傳圖片或輸入關鍵詞,再選擇平台給予的風格,幾秒之後就能生成圖片,其超絕的想像力被無數用戶玩出了花:

圖源:網絡
還有通過聊天出畫的Midjourney,用戶進入聊天軟件Discord,並被邀請到相應的小組中後,就能像是真的與畫手隔着網線交流一樣,說出自己的需求,而AI也會在群中實時更新的繪畫進度:

圖源:網絡
OpenAI上個月剛剛推出的Dall-E2,其生成結果的精準度、對人物的識別能力震驚了整個技術圈,甚至都有讀者用這一AI出了一整本畫集,整整1000張圖片:

圖源:作者個人主頁
更不用說谷歌新鮮出爐的Imagen,不管多長,多具體,多不符合現實邏輯的離奇描述詞,都可以精準地從文字生成真實準確的圖像:
圖源:谷歌官網
驚人的技術疊代速度、破圈式的熱度、震驚了繪畫圈的色彩、構圖、想像力和創作力,似乎都在表示,這些AI畫手們,正在逐漸在繪畫領域中掌握」畫語權「。
對此,有人歡欣鼓舞,認為技術的革新將為藝術領域帶來全新的思考方式和改變,有人惶惶不安,擔憂來勢洶洶的AI畫手將摧毀一大批中低端繪畫崗位,甚至有人怒斥AI將藝術變為了單純的數據遊戲,使得繪畫失去了意義和靈魂......
議論連續不斷,熱度居高不下,AI繪畫這一名詞開始逐漸出圈,在谷歌的關鍵詞搜索趨勢中,AI painting的搜索熱度自去年下半旬就開始逐漸高漲,到現在已經達到了一個新的高峰:
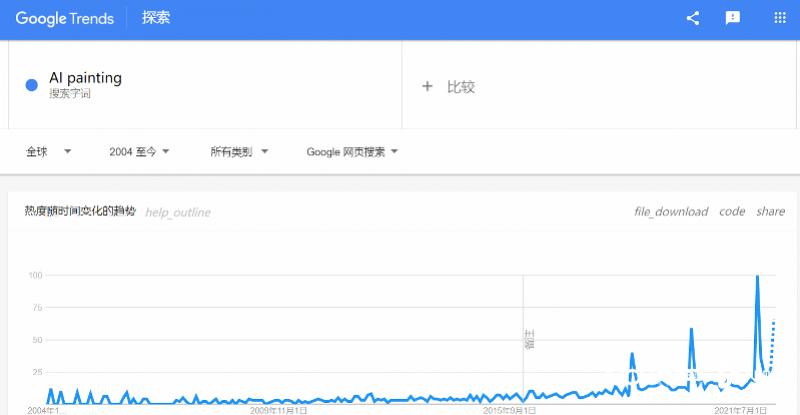
熱議之下,已經有這樣的聲音出現:
AI繪畫,元年已至。
···
且先不論這一發言是否正確,所謂的AI畫作,到底是嚴格按照代碼邏輯運行,風格單一的產物,是AI的隨機拼接遊戲,抑或是真能如人類畫手一般依照主題構想畫作?
AI們都畫了什麼,它們又能畫多少?
AI畫手的第一批體驗者們,當時就抱有着這樣的疑惑。PPT設計師阿文就是其中之一。
今年4月份時,他偶然看到一個畫手朋友在微博展示了一組AI作畫的作品,效果驚人,朋友作為專業畫手也給予了很高的評價,他便也對這個叫做Disco Diffusion的工具起了興趣。
這是一款基於谷歌的技術框架開發的AI作畫工具,部署在谷歌Colab(一個可以通過瀏覽器編寫和執行代碼的線上託管平台)上,訓練畫作所需的算力也由谷歌免費提供,而只需要修改代碼中的一個部分的文字描述,就能生成畫作:
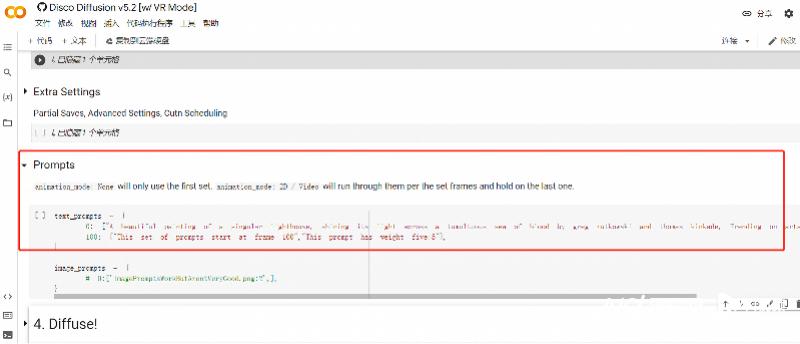
文字描述擁有畫種描述、內容描述、畫家描述、參考渲染方式、顏色描述五個維度,用戶不用修改代碼,而是只要從這幾個方面進行調整和修改,就可以生成圖像。
不過,鑑於是初玩,阿文只謹慎地修改了默認文本中的兩個關鍵詞:A beautiful painting of astarry night(原singular lighthouse), shining its light across asunflower sea(原tumultuous sea)by greg rutkowski and thomas kinkade, Trending on artstation.」"yellow color scheme「,也就是將默認的」一座在驚濤駭浪中閃耀的奇異燈塔」改成了「一片在星空下閃耀的向日葵花海」。
而AI吐出的第一張圖片是這樣的:

圖源:Simon_阿文微博
這是一張超乎了阿文想像的畫作,色彩、構圖都擁有超絕的美感和想像力。
而Disco Diffusion本身可以根據一句描述產出多張不同的圖片,於是,阿文在無比期待中,迎來了掛機渲染之後的另外幾幅作品:

圖源:Simon_阿文微博
簡單的文字描述外加一點點天賜般的運氣,誕生了數張色彩構圖豐富大膽,如同夢境般的畫作,最終一舉出圈,在微博超過兩萬人轉發,並紛紛表示震驚「給跪」。
也因此,大批用戶紛紛湧入,開啟了腦洞大開的AI花式作畫。
有將參考畫師改為吳冠中,直接得到一張水墨畫:

圖源:網絡
還有應用了虛幻引擎風格,生成的仿佛遊戲頁面一樣的畫作:

圖源:網絡
當然,偶爾也會有人餵出了一些有些詭異的圖片:

圖源:推特Mike Franchina
......
在那之後,阿文也試用了另一款叫做Midjourney的工具,同樣是「星空下的向日葵海「的描述,不過這次的生成結果則恰如其分地落在了他的想像力內:

圖源:Simon_阿文微博
「就像是一個聽話版的Disco Diffusion。」阿文笑道。
在嘗試多次後,他覺得Midjourney的想像力是比不上Disco Diffusion的,但好處是速度夠快,五分鐘就能成圖,而且不至於像Disco Diffusion那樣,有搶奪創作主導權的「野心」,是更適合藝術創作者的輔助工具。
還有更多像阿文這樣的藝術創作者,走上了探索AI繪畫工具的道路,並開始逐步挖掘各自的潛力。
比如主陣地是移動端的Dream,它的整體作畫風格更偏向於夢幻柔和:

圖源:網絡
而諸如DALL·E2、Imagen之類的畫手,則是在如何更準確地理解文字描述、更好地組合繪畫風格,最後生成更精確而言之有物的事物和人物的方向努力。
當然,除了這些從無到有的「高端創作者」,近幾年也火過一批更加親民的AI畫手們。
比如在去年一度火爆外網AnimeGAN,可以實時地將人像轉為漫畫模樣,也是在線部署,火到要排隊幾個小時才能玩到:

圖源:網絡
去年在日推被瘋轉的AI,簡陋的草圖一經它手就會變成精緻可愛的二次元萌妹:

圖源:高坂推特視頻
還有可以任意推斷兩張人物圖像的子世代長相的Artbreeder,不僅幾秒就能出圖,還可以通過超多參數微調產出人物的長相:

圖源:網絡
再出圈一點,抖音、微信或QQ中的將人物照片轉變為其他風格的AI濾鏡,也能被算進AI作畫的範疇里。
這樣看來,AI畫手們作畫內容的範圍覆蓋之廣,比起一些人類畫手也是不遑多讓。
其屢屢出圈的熱度,更證明了在普通觀眾眼中,AI的畫作們有着足夠的衝擊力和觀賞價值。
···
接下來,讓我們換一個角度來看AI繪畫。一張成品畫作由什麼組成?在現實中是紙張和各種材料製成的筆墨水彩,而儲存在電子設備中的一張圖像,本質上則是一個像素點矩陣,每個都由 RGB(Red、Green、Blue)三個顏色通道組成。
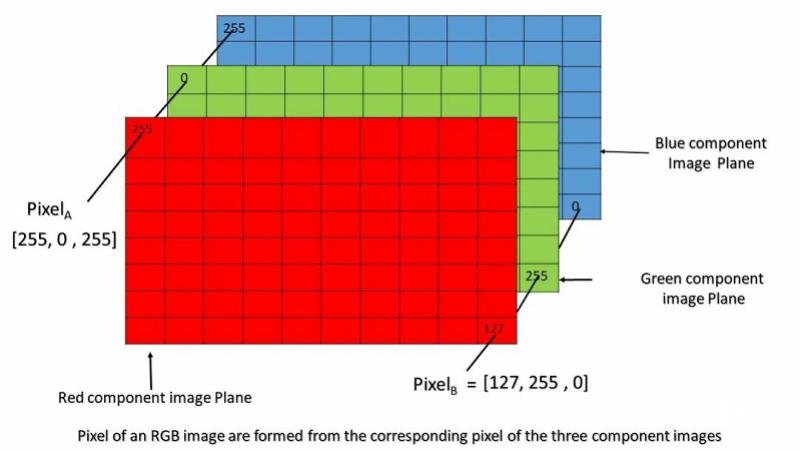
圖源:網絡
因此,AI繪畫也就相當於一個可以逐漸產生像素,進行圖像生成的計算機模型。
模型是人工智能中的一個概念,我們可以將其通俗地理解為一種從輸入到輸出的函數。
要讓這個函數輸出我們期待的像素點矩陣,首先需要賦予它很多「參數」,相當於函數中的變量,這些變量涉及繪畫中每一筆的位置、形狀、顏色,甚至是覆蓋關係、筆觸組合等多個屬性。
有了這樣一個擁有龐大「變量」的「函數」,還要再基於海量的已有圖像進行訓練,也就是找到效果最好,最合適的一組參數的過程。
而這樣一個繪畫模型所需的參數量和訓練數據集非常龐大,不僅如此,也很難讓計算機去理解「創作」這種比較抽象的概念。
因此,誕生之初的AI作畫,說是依照邏輯執行任務也並無不妥。
轉機則發生在2014年。
這一年,一位名叫Ian Goodfellow的AI從業者發明了一種叫做對抗生成網絡(Generative Adversarial Network,簡稱GAN)的算法,徹底改變了圖像領域。
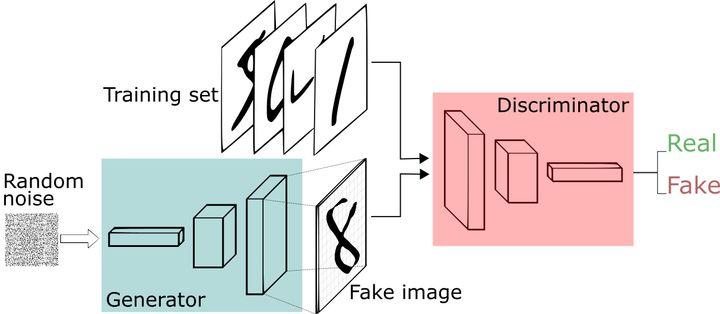
圖源:論文
對抗生成網絡主要包含兩個結構,一個是生成器(Generator),一個是判別器(Discriminator),而其核心思想則是「對抗博弈」,我們可以感性地將其理解為「道高一尺,魔高一丈」。
什麼意思?生成器的主要任務是生成儘可能真實的圖像,而判別器則負責辨別眼前的圖像到底是有機器生成的,還是來源於真實世界的圖片,這樣,生成器在圖片生成的過程中「造假」技術變得越來越強,而判別器的「打假「技術也將越來越精湛,在這雙方的對抗博弈之中,最終產出的圖片也將越來越真實。
對抗生成網絡提出的兩年內,圖像生成任務有了大跨步的發展,一些有趣的應用,如老照片修復、換臉、素描上色,更是如雨後春筍一般應運而生。
我們上面所提到的Artbreeder、草圖生成頭像等從已有圖片合成新圖片的應用,也是在此之後開始有了萌芽。
而在2016年,Scott Reed等AI研究者又首次提出了基於GAN的文本生成圖像(Text to Image)。
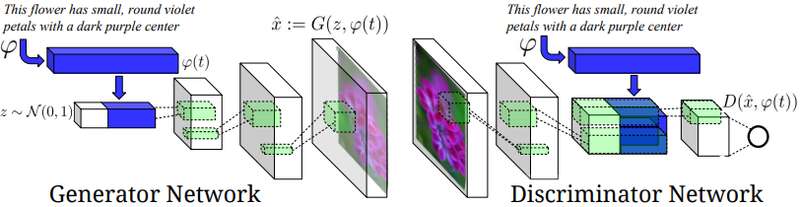
圖源:論文
就像人類擁有五感一樣,AI也有自己聽覺和視覺,也就是AI研究者們劃分出來的計算機視覺(Computer Vision,簡稱CV)、自然語言處理(Natural Language Processing,簡稱NLP)、語音識別(Automatic Speech Recognition,簡稱ASR)等研究領域。
而文本生成圖像,則是將計算機視覺的自然語言處理兩種領域連接了起來,也被稱為多模態學習(MultiModal Learning),可以說,這種技術是今天AI繪畫的重要基礎。
但要讓AI學會」通感「,難度也可想而知,一開始,AI只能在受限的數據集內取得成果,得到的解像度也不高,同時,AI也受限於機器對於人類自然語言的理解,因此,文本生成圖像的進展並不迅速。
直到2021年1月5日,DALL·E模型橫空出世。

圖源:OpenAI官網
模型的出生地,OpenAI實驗室是全世界最著名的AI實驗室之一,2015年底成立,同為特斯拉、SpaceX,以及推特等多家公司掌權人的AI產業界頂流馬斯克,就是這家實驗室的創始人之一。
而模型的名字DALL·E取自超現實主義藝術家薩爾瓦多·達利(Salvador Dali)和皮克斯機械人WALL-E,可以從文字說明直接生成圖像。
DALL·E對圖像生成領域投下了一記重磅炸彈,圈內諸多大佬轉發點讚,其本身更是被稱為2021年第一個令人興奮的AI技術突破,甚至被譽為幾乎實現了類人智力的模型。
究其原因,則是因為它在文本生成圖像上的驚人表現。
基於同在OpenAI開發的模型,也就是擁有1750億的巨量參數,截至現在仍是業界公認最強的語言模型GPT-3,DALL·E在語言理解上的能力有了一個驚人的提升——
能夠創建擬人化(即類人)的動物和對象:

圖源:OpenAI官網穿着芭蕾裙遛狗的小白蘿蔔插畫
能將某些對象或概念合併至單個圖像中:

圖源:OpenAI官網由豎琴製成的蝸牛,帶有豎琴紋理的蝸牛
還能補全圖像的缺失部分、控制場景的視點和渲染場景的3D樣式、將某個對象的內部和外部結構全部都」想像出來「。
其實,OpenAI同天還推出了一款叫做CLIP的技術框架,這一款能將文本與圖像聯繫起來的特殊的」圖像識別「,與一般的通過自行車、蘋果等確定單詞識別圖像不同,它是通過一段文字描述來識別圖像的。

圖源:OpenAI官網
以這兩款技術的誕生為標誌性事件,語言理解和圖像生成任務多年來的技術積累,以」AI作畫「為載體,開始集中爆發。
2012年底,基於類別引導的擴散模型(Guided Diffusion)出現,再結合CLIP,一併組成了上文中提到的火爆全網的Disco Diffusion背後的核心技術。
準確地說,Disco Diffusion會先通過圖像擴散模型(Diffusion Model),對現有的生成圖像進行一次又一次的」去噪「,也就是減少圖像生成中的干擾部分,使其變得越來越清晰的一個過程,反覆進行這個過程就被稱為」疊代「。
而在每次疊代時,CLIP則負責利用其圖像識別技術,依據文本提示對現有的圖像擴散模型進行評估,並為其提供下次疊代的」方向「,這樣,生成的圖像也就會和文本提示的匹配度越來越高,圖像的精細度也會逐漸增加。
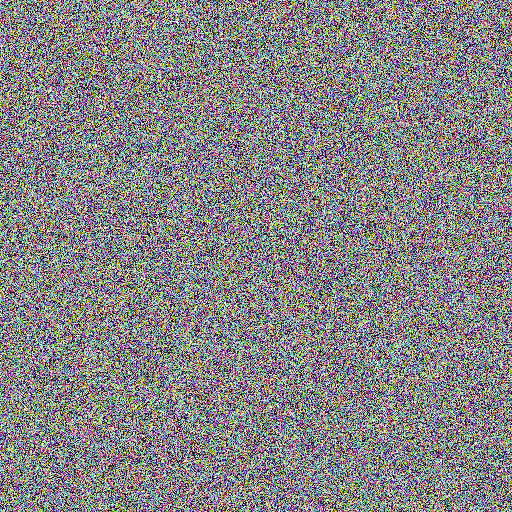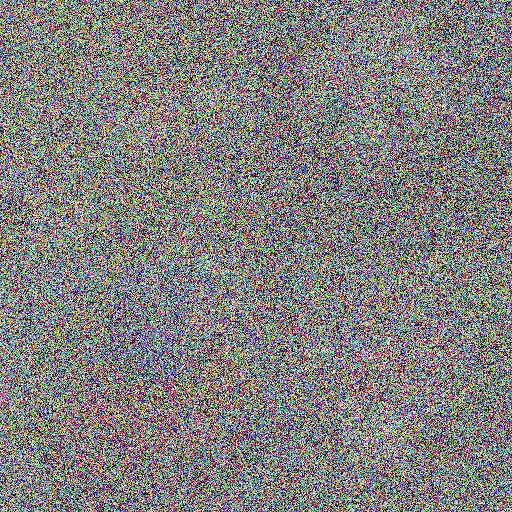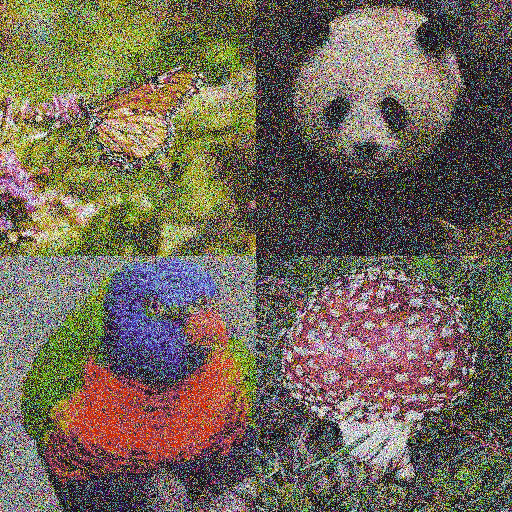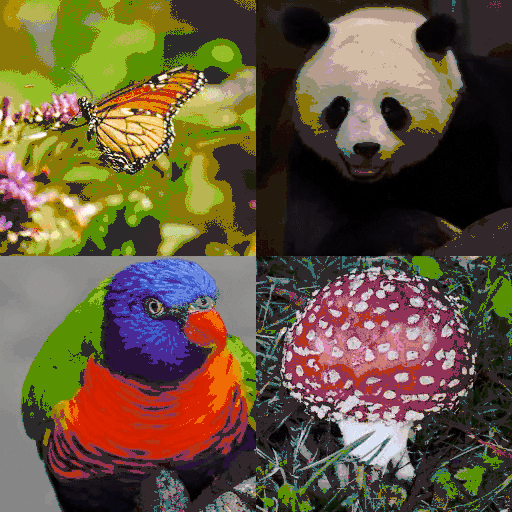
圖源:網絡
就這樣,CLIP負責從文本特徵映射到圖像特徵,然後指導一個生成對抗網絡或擴散模型生成圖像,自此之後就成為了文本生成圖像的一種基本」套路「。
這還沒完,今年4月份,OpenAI對DALL·E做了升級,推出了更高解像度、更低延遲的DALL·E-2:

圖源:OpenAI官網
這一技術架構已經脫離了簡單的素材拼接,而是確實理解了許多抽象概念——比如空間、光照,甚至是對現實中不存在的圖像的想像:

圖源:OpenAI官網太空人在太空中騎着一匹馬
但文本到圖像領域的SOTA(State Of The Art,指在特定任務中目前表現最好的方法或模型)才被OpenAI保留了一個月,谷歌就站了出來——
5月24日,谷歌大腦研究團隊推出了Imagen模型,使得機器的想像力又到達了一個新的高度。
在論文中,Imagen與其他圖像生成模型都在目前最有影響力的計算機視覺數據集之一的COCO上進行測試,與DALL·E,DALL·E2,GLIDE等同領域模型對比,Imagen生成的圖像與真實圖像的差別是最小的。隨着一個又一個革命性的技術框架出現,一個又一個具有影響力的科研團隊進入賽道,AI作畫開始從粗糙走向專業。從AI的隨機組合遊戲,到理解文本描述開始」想像「,AI是真的一步一步拿起了畫筆。
···
"我認為今年就是AI繪畫元年。"
PPT設計師阿文這樣表示。
數量井噴,技術疊代速度極快的AI繪畫工具,不僅熱度出圈,身邊的藝術設計、繪畫等領域的很多專業畫手們也紛紛給予了非常積極和正面的評價。
尤其是其所展現的「想像力」,幾乎是將手伸到了人類認為只有自己才能做到的領域,背靠網絡上現存的所有圖像庫,再加上驚人的識別能力和融合速度,AI總是能在極短的時間內產出各種匪夷所思的繪畫思路和結果。
於是,這樣一個觀點逐漸在焦慮中成為了一種主流:
AI畫手會不會代替掉一些中低端畫手?
對於這個問題,阿文給出了否定的回答:
」即使是現在大熱的Disco Diffusion和DALLE·E,也沒有投入到生產項目當中,因此最多接觸到這些工具的人群,依然還是圈內的設計師們,所做的也都是前沿的嘗試,還沒有到產品商業化的地步。「
而且更重要的一點是,現在的AI畫手對於真正的甲方來說,還不夠」聽話「。
比如,就當下的AI繪畫來說,「關鍵詞」極其重要,如何編寫結構合理,語句優美的英文描述句,以便於AI充分識別和理解,這是出畫的核心。
對關鍵詞的極高要求,使得AI作畫並不能像很多人類畫手那樣」指哪打哪「,尤其是在面對一些莫測難尋的甲方需求時,就顯得更呆了。
圖源:Simon_阿文微博與友人的吐槽
並且,關鍵詞稍有不慎,人工智能就可能不再智能。
比如像這張畫,將動畫大師」宮崎駿「加入描述詞後,AI直接將老人家的頭像生硬拼湊到了畫面中:

圖源:網絡
這也是AI繪畫廣為人詬病的另一點:在具象內容,尤其是人物生成上的能力偏弱。看似衝擊力十足卻缺乏邏輯和細節的畫面,沒有哦內核的概念拼湊......還有更多問題,都使得AI作畫不可能百分之百地展現完美的效果。

圖源:網絡 wombo生成的沒有意義的色塊拼接
因此,至少對現在的AI繪畫工具來說,人類畫手後期的調整和加工必不可少。
並且,技術較為前沿,且需要一定藝術知識的AI作畫工具,最先接觸與最熟悉的第一批用戶,一定也都是畫手和設計師,即產業中的乙方。而且越到後期,AI工具就越需要關鍵詞輸入之外的更多知識,比如具體到代碼層面的參數調整。因此,即使是走到了產業化的一步,甲方首先接觸到的,也更有可能是」會使用AI的乙方「,而並非AI本身。
作為」會使用AI的乙方「的阿文,還提出了另一種觀點:
AI繪畫的出現,反倒會讓很多畫手有了新的契機,能夠藉助AI工具成為高端畫師。
畫工、想像力、底圖、靈感......諸多不足都可以由AI繪畫工具來補足,只要在這些圖的基礎上進行二次創作,就很有可能夠到更高的門檻。
阿文現在就在努力將AI繪畫工具納入自己的工作流程中,比如他在微博就展示過這麼一個例子:首先用Disco Diffusion生成相應的紋理,然後再到三維建模工具blender里貼圖,最後再搭場景:

圖源:Simon_阿文微博
至於版權問題,阿文表示,AI作畫工具在使用時,確實有通過描述詞進行了「畫風抄襲」的可能性,因此他建議,儘量使用已經過世的藝術家的風格,如果使用了某位風格鮮明的當代藝術家作為關鍵詞,或者使用了某部商業作品作為參考畫作時,還是儘量避免商用。
不過他也提到,比如Disco Diffusion並不是所謂的描圖、素材拼接或組裝,而是依據技術框架對圖像進行了規律和技法的提煉,然後再進行模仿,所以「畫風抄襲」的風險不是很大。
另外,Disco Diffusion現在的所有代碼已經開源,且遵循MIT開源協議,也就是別人可以進行閉源修改代碼,且無須經過版權說明,就能複製甚至銷售衍生的產物:
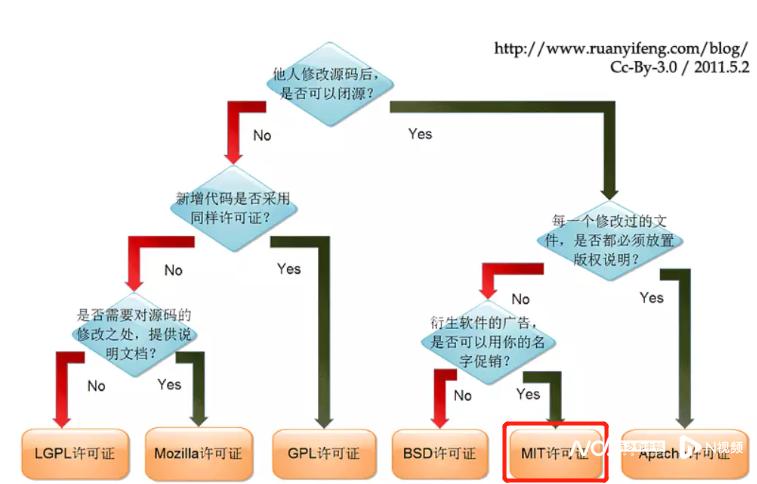
圖源:阮一峰博客
至於一些二次元頭像生成器,阿文則開玩笑地表示「技術不到家,抄得還不夠像」,因此甚至都到不了「畫風抄襲」的地步。
···
然而,上述解答依舊不能讓所有人安下心來。
在更深層次的思考中,有人擔心AI是否會殺死繪畫的意義,就像當年的攝影技術之於寫實繪畫,或者像今天的AI之於圍棋。
攝影技術誕生於兩百年之前,一經應用便迅速取代了繪畫的記錄留影功能,一度使得諸多傳統畫家認為繪畫將在攝影技術下的逼迫下逐漸消亡。
而AI進入圍棋則始於2014年的AlphaGo,在人工智能那幾乎是無法超越的計算能力下,多國的圍棋黑馬和明宿皆被一一斬於馬下。
「但是攝影之於繪畫藝術,其實並沒有嚴重到『摧毀』的地步。」
阿文解釋道。
當時的繪畫看似在攝影的「逼迫」下失去了其實用價值,轉為了純粹的藝術領域,但實際上,攝影在視覺經驗上的真實性,使得很多畫家開始更多地關注繪畫本身的特質,試圖以繪畫對現實乃至精神世界進行更豐富的演繹,後印象派、野獸派等新興流派就是因此得而誕生。
而到了今天,攝影不僅有最實用的記錄功能,自身也是一門獨立的藝術學科,有着構圖和色彩領域的只是體系;而繪畫在藝術性不失的同時,留影功能也開始逐漸復甦,甚至因為其獨特的筆觸帶來了更多美的享受。
而類比到AI繪畫上來也一樣,這無疑是對於現在繪畫的一種衝擊,但新老技術之間並非你死我活的競爭關係,而是相互融合,共同進化發展的一種趨勢。
那麼AI圍棋的到來呢?
柯潔曾評價AI時代的圍棋為「無聊透頂,使人類棋手喪失了存在的意義」,在諸多的AI大戰人類棋手,AI預測圍棋勝率的事件中,已經有觀眾開始對這種戲碼失去興趣:
圖源:網絡
因此,有不少人便也覺得,AI繪畫會像AI圍棋一樣,逐步殺死繪畫的意義。
一位畫師在談論這一話題時,表達了如下觀點:
「我覺得藝術創作很多時候是基於藝術家較獨一無二的性格、境遇、或者一閃而過的某種激情,是為了抒發自我,表達內心的感情而存在的。但AI只是基於圖像庫去分析並重組,並沒有任何目的和情緒,所以實在難以稱得上是『具有靈魂』。」
但具有靈魂,產生共鳴,一定是要了解作者背後的情緒嗎?
阿文舉了一個這樣的例子:當你走進一個美術館,看到一幅畫,然後被打動了,很多時候你可能不知道背後的作者是誰,要抒發什麼樣的感情,但有些畫作就是能在觀眾看見的瞬間,便與其產生共鳴,而觀眾能產生這樣的感受,這幅畫作就是有意義的。
而當我們再回過頭,去看那張出圈的「星空下的向日葵海」,到這裏,我們已經完全知道了這幅畫作創作的全過程,及其中的技術細節,也知道AI在創作這幅畫的時候是不具有任何,或者說類似人類畫家那樣的情緒。
但翻開這幅作品的評論和轉發,即使知道這是AI,依然覺得「充滿意境」「浪漫無比」「有被感動到」的評論數不勝數。
「就像是AI在賽博朋克時代夢到了梵高。」

AI繪畫背後的技術仍在快速疊代,產出的畫作越來越多,而關於其產出作品有無意義的爭論,在可預見的未來仍將繼續。
AI繪畫的終點是什麼?是成為人類畫手最完美的繪畫輔助者,還是一步一步補足其邏輯性、想像力、創造力,成為一名真正可以與人類並肩的畫手?
我們現在也只能站在星空下的向日葵海中,靜靜等待那個答案的到來了。
















{kind=link}