當前AI杜撰歷史事件、編造虛假法律條文、偽造學術參考文獻的現象已屢見不鮮。它帶來的危害早已超越簡單的「口誤」範疇,不斷侵蝕公眾對AI的信任。
就在上個月,全國首例AI幻覺侵權糾紛案正式宣判,這一標誌性事件意味着AI幻覺已從單純的技術問題,升級為亟待解決的法律與社會問題。隨着大模型深度融入我們的工作與生活,其潛在風險正影響着越來越多的普通人。
那麼,到底什麼是AI幻覺?為什麼AI總能以無比自信的語氣說出完全錯誤的內容?這背後藏着大模型最核心的運行邏輯。
據央視報道,究其根本,AI幻覺是大模型底層機制必然帶來的系統性風險。很多人誤以為AI像人類一樣通過認知世界來學習知識,但事實並非如此。
AI娓娓道來的流暢表達背後,本質上只是從海量文本數據中學習詞語、句子之間的統計關聯,再根據上下文預測下一個最有可能出現的詞。
打個最通俗的比方,小朋友認識「蘋果」,是通過看見它的顏色、摸到它的質感、嘗到它的味道,在大腦中形成關於蘋果的真實概念。
而AI認識「蘋果」只做一件事,即統計詞語共現概率。它從億萬篇文本中發現,「蘋果」常常和「紅」「甜」「脆」「水果」等詞語一起出現,於是就能流暢地說出「紅蘋果口感甜脆」這樣的句子。它不是真的懂蘋果,只是說得像懂而已。
這種運行機制決定了,當問題過於冷門、專業,或者涉及大量具體細節時,一旦模型在訓練語料中缺乏足夠的相關案例,就無法計算出可靠的詞語概率,此時它不會選擇「不知道」,而是會根據統計規律強行拼接出看似合理的內容,這就是AI幻覺的根源。
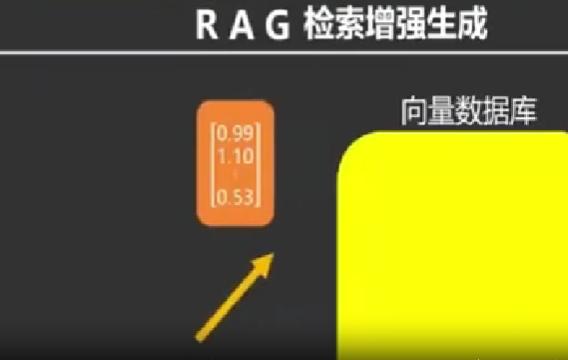
對此,全球科技行業正在積極探索破解之道。目前最主流的解決方案是檢索增強生成技術(RAG),其核心思路是讓AI在回答問題前先檢索權威數據庫中的資料,相當於把「閉卷考試」變成「開卷考試」,能大幅降低AI編造虛假信息的概率。
而最前沿的技術方向,則是讓AI自己「吵一吵」來逼近真相。清華大學等機構提出的多智能體辯論框架,相當於讓多個AI化身不同立場的專家,針對同一問題相互質疑、交叉驗證,最終篩選出最可靠的結論。
除了行業層面的技術攻關,普通用戶掌握正確的使用方法,也能有效規避AI幻覺的陷阱。具體來說,只需記住兩點:
一是要巧問,提問時儘量給出明確的範圍、限制和要求,比如「請基於2025年最新的《民法典》回答」「只引用官方發佈的數據」,減少AI自由發揮的空間;
二是要善查,對於涉及法律、醫療、財務、學術等關鍵領域的信息,必須通過權威渠道進行核對,也可以同時使用多個不同的大模型進行交叉驗證。
誠然,受限於當前的技術水平,AI或許永遠無法做到100%沒有幻覺。
但正是這種「不完美」提醒着我們,在享受AI帶來便利的同時,我們要保持獨立思考和批判性思維,才是應對AI挑戰的最佳方式。
















{kind=link}