GPT-5.5,終於發佈。
作為OpenAI當下最強的模型,這次更新的亮點是「為真實工作而設計」。
和過去的模型相比,GPT-5.5能更快理解使用者真正想做的事情,也能自己承擔更多執行過程,可以在線檢索信息、分析數據、生成文檔和表格、操作軟件,並在不同工具之間來回切換,直到把任務完成。
用戶不再需要精細地拆解每一步,可以直接給它一個混亂、多步驟的問題,讓它自己規劃路徑、調用工具、檢查結果,在不確定中繼續推進。
有網友直接評價,這是目前為止最接近AGI的模型。
目前,GPT-5.5已經在ChatGPT和Codex中向Plus、Pro、團隊版和企業版用戶逐步開放,GPT-5.5 Pro則面向Pro及以上用戶。API版本尚未上線。
模型性能
先來看看模型在基準測試中的得分情況。
其中最值得關注的指標是GDPval,這個測試不是傳統選擇題,而是用44種真實職業任務來評估模型,比如分析數據、寫報告、做判斷。
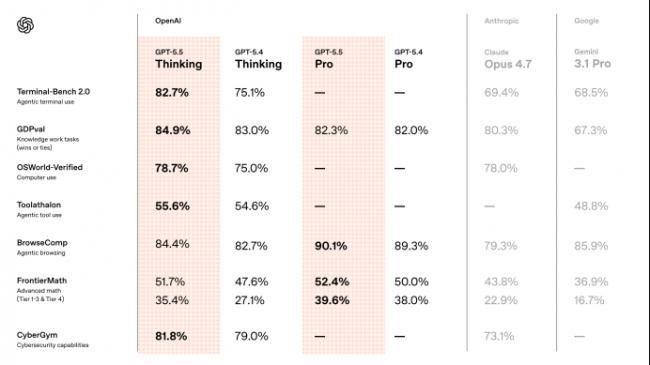
GPT-5.5的成績是84.9%,相比GPT-5.4的83.0%,有一定的提升,也高於Claude Opus4.7的80.3%和Gemini3.1 Pro的67.3%。
第二個關鍵測試是OSWorld,用來衡量模型在真實電腦環境中的操作能力。GPT-5.5達到78.7%,高於GPT-5.4的75.0%,提升幅度不算誇張,但意義很大。
這項能力考驗了一個更現實的問題:模型不僅能告訴你怎麼做,還能不能直接替你去做,包括點擊界面、切換工具、執行多步驟操作。
還有Tau2 Telecom,這是一個電信客服流程測試,GPT-5.5在無需額外調優的情況下達到98.0%。這類任務更接近企業里的真實工作,需要在複雜、多步驟、有上下文依賴的流程中完成。
在更細分的能力上,GPT-5.5的編程能力繼續提升,在Terminal-Bench2.0上達到了82.7%,在SWE-Bench Pro上達到了58.6%。
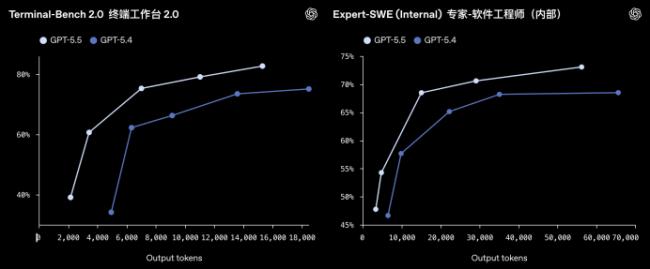
在其他知識工作基準測試中,GPT-5.5的表現也很出色:FinanceAgent得分60.0%,內部投資銀行建模任務得分88.5%,OfficeQA Pro得分54.1%。說明它在結構化分析和數據處理上已經相當成熟。
科研方面雖然分數提升相對溫和,但已經出現能夠參與推理、驗證甚至輔助發現新結果的案例,這一點更像能力邊界的變化,而不是簡單的性能增長。
把這些跑分放在一起看,會發現這次模型的評價標準正在發生變化:過去我們常用MMLU、GPQA這樣的指標看模型的知識和推理能力,但現在更側重於GDPval、OSWorld這類「任務級評估」。
相比起問模型知不知道某項知識,現在更看重它能不能完成一項完整工作。
這也對應了GPT-5.5本次的更新重點。模型開始能夠自主地組織步驟:先獲取信息,再做判斷,必要時調用工具,最後把結果整理成可以直接使用的輸出。
在編程上,它參與整個開發流程,而不只是生成代碼;在知識工作中,它產出報告、模型和決策建議,而不只是提供答案;在操作層面,它甚至可以直接進入電腦環境,把這些步驟執行出來。
這一代模型更像一個可以協作的執行者,得分只是表面,更重要的是這些分數背後指向的一件事:GPT-5.5的定位,從「回答」轉向了「執行」。
順便一提,根據ARC Prize官方驗證,GPT-5.5在ARC-AGI-2基準測試中取得最高85.0%的準確率,成為了新的SOTA模型。

除了能力本身,這一代模型還有一個被反覆強調的點:效率。
OpenAI給出的數據是,在實際服務中,GPT-5.5的速度與GPT-5.4基本持平,但在完成同樣Codex任務時使用的token明顯更少。這一點對API用戶尤其重要,因為它直接決定了真實使用成本。
在定價上,GPT-5.5 API為每百萬輸入token5美元、輸出30美元,Pro版本更高。這個價格是GPT-5.4的兩倍。
不過OpenAI的邏輯是:單價雖然提升,但由於任務完成效率更高,總成本未必上升。

另外,安全體系也在同步升級:GPT-5.5是目前防護最嚴格的一代模型,在發佈前經歷了完整的安全評估流程,包括內部與外部紅隊測試,以及針對網絡安全、生物等高風險能力的專項驗證,並結合了近200個真實使用場景進行調整。
模型表現
作為一個擅長複雜任務的模型,GPT-5.5的編碼優勢在Codex中表現尤為突出,可以完成從實現和重構到調試、測試和驗證等工程工作。
根據官方文檔,它在真實工程上表現很好:在大型任務中能夠持續保持上下文(不會只盯着一小段代碼);在問題不明確時,能夠推理出故障原因;會用工具去驗證自己的假設;能把修改真正「貫穿」到整個代碼庫,而不是只改一處。
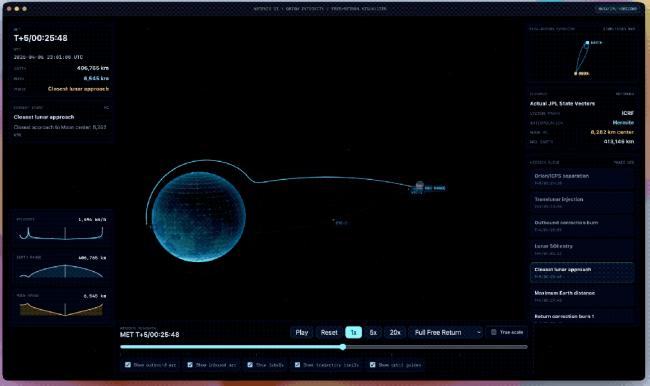
官方給出了一些比較複雜的示例,例如把一張天體圖片重新做成一個新的Web應用。
技術上要求用WebGL做3D渲染、用Vite搭項目,內容上要儘量接入ArtemisII任務的真實數據,把軌道、飛行路徑、天體位置這些信息真實地表現出來。
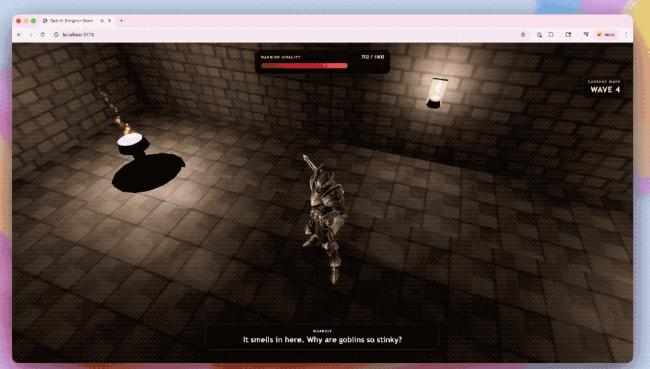
還有讓GPT-5.5結合Codex生成的3D地牢競技場原型。
模型不僅搭建了遊戲架構,還寫出了基於Three.js的前端實現,並覆蓋了戰鬥系統、敵人機制和界面反饋等關鍵模塊;環境貼圖和角色對話也由GPT生成。只有角色模型和動畫交給了第三方工具處理。
在編程能力之外,GPT-5.5的能力已經延伸到更廣泛的知識工作,由於它更擅長理解真實意圖,所以可以更自然地跑完整個知識工作的流程:從獲取信息、抓住重點、調用工具、檢查結果,到把原始材料整理成真正有用的輸出。
在Codex里,GPT-5.5在生成文檔、表格和演示文稿方面,比GPT-5.4更強。OpenAI內部已經在真實工作中使用這些能力:目前,公司內部超過85%的員工每周都會使用 Codex,覆蓋軟件工程、財務、傳播、市場、數據科學和產品等多個團隊。
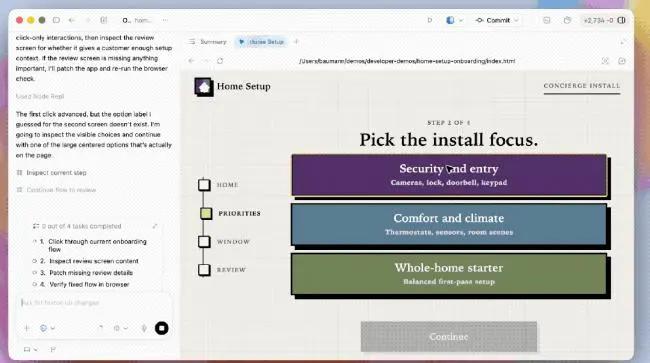
例如下列演示,就是使用GPT-5.5生成財務建模。
除了官方的複雜demo,為了看清模型在「單次生成」層面的表現,我們也做了一些更偏基礎能力的測試。
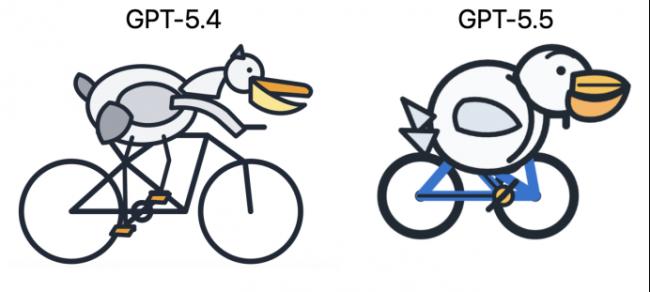
首先是每次都被拉出來的鵜鶘騎自行車,左邊是GPT-5.4的表現,右邊是GPT-5.5。
還有六邊形小球滾動,可以看模型的物理理解。

在審美上,我們用一句話讓GPT-5.5設計了一個高端品牌網站,效果如下。
prompt:Design a premium brand website with a strong identity, focusing on typography, spacing, and a cohesive visual style. Avoid generic layouts.Use Chinese.Can run entirely in a single HTML file.

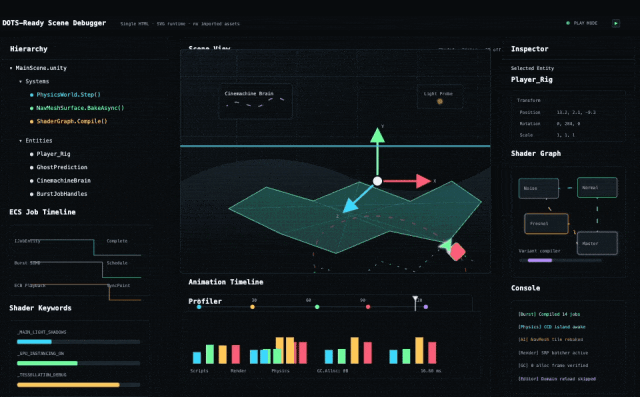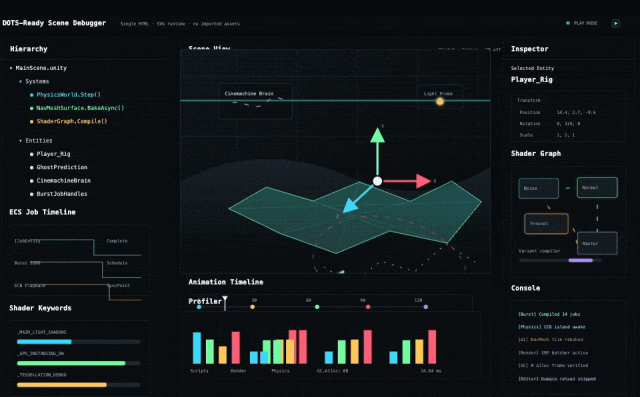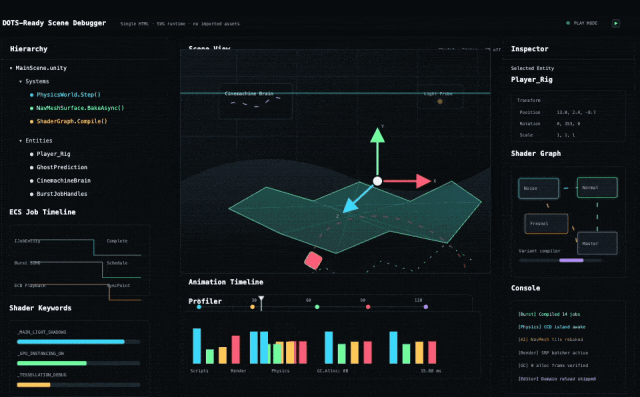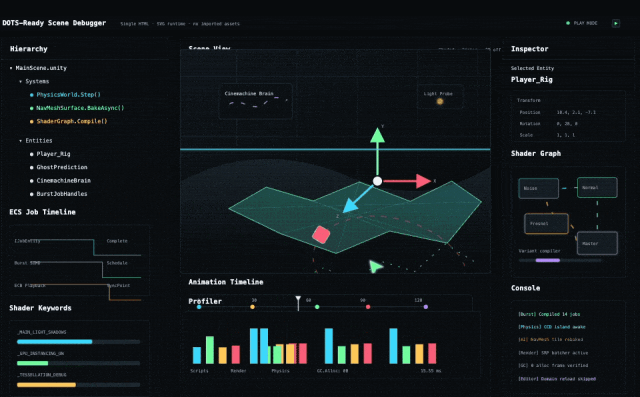
接下來讓它自由發揮,創造一個Unity風格的複雜SVG動畫。
prompt:Create a complex svg animation that an engineer with a background in unity would appreciate.Can run entirely in a single HTML file.
編程能力之外,像在社媒上很火的洗車問題,我知道肯定也會有人想問。

這類問題一般難以回答的原因是,模型並不會默認車一定要開過去才能洗(可能有上門洗車的服務)。不過既然需要「理解用戶真實意圖」,我想這並不是什麼答錯的理由。
模型定位
如果把GPT-5.5放在過去這一年的演進脈絡里看,它並非單純地圍繞模型能力做提升,而是在逐漸改變模型的使用方式。
這條線其實可以從GPT-4o開始算起。當時最大的變化是把文本、圖像和語音放進同一個模型里處理,多個能力被放在同一個系統中完成,模型的內部開始變得統一。
GPT-5把這種「統一」延伸到了使用層。模型不再只是等待用戶提問,然後給出一次性儘可能完整的回答,它多了一層判斷:這個問題需要多快的響應、多深的推理,要不要調用工具。
後面的幾個5系版本,基本都在把這件事做細。
在GPT-5.3這一階段,編碼能力和工具調用被明顯強化,模型開始更穩定地完成多步驟代碼生成、調試和執行流程。它不只是寫代碼,還會自己一步步改、修錯誤,最後給出一個能用的結果。與此同時,它用工具的方式也變得更自然,不再是生成一堆看不懂的調用代碼,而是直接把該調用的工具給用上。
到了GPT-5.4,重點已經轉向computer use和工作流能力,模型可以在不同應用之間來回切換,比如查資料、整理信息、再生成結果,一步步把事情做完。同時,響應速度、token利用率和長任務中的穩定性也在持續優化:它的反應更快了,回答更乾脆,不再動不動就寫一大段推理過程,在連續做一件事的時候,也更少出現前後說不一致的情況。
這些調整放在一起,能看出一種變化:模型開始更像一個在後台持續運轉的系統,而不是一次性的問答工具。
用戶與模型之間的關係也在發生變化,從一問一答,變成把一件事情交給它,然後看它一步步往下做。
順着這條路徑看,GPT-5.5的位置就比較清楚了。它不只有性能上的提升,還在繼續把模型往任務執行的方向推進。
OpenAI將這一次的升級稱為「very strong model」、「為真實工作而設計的一類新智能」,強調模型在持續運行時的效率和穩定性,比如在更長時間內完成一整套流程,用更少的計算支撐更多步驟。
很多人會同時感覺它更快了,也更「短」了,本質上是模型開始主動控制自己的計算方式,把更多資源留給真正需要展開的部分:單次回答不再一味追求展開,而是更貼近任務本身的需求。
對於需要連續操作的場景來說,這種變化非常有價值。同樣一件事可以用更少的token完成,不僅是體驗上的提升,也直接影響到最終的成本。
當模型開始承接完整流程,評價標準也會隨之改變。比起單次回答的好壞,更重要的是它能否穩定高效地把一件事做完。
畢竟,更適合真實工作場景的模型,才是好用的模型。

















{kind=link}