人們聽廣播的時候,腦海中會幻想出說話者的樣貌,
她可能是個面容清秀、身材瘦小的年輕女孩,他也可能是個四十出頭、臉長肩寬的中年男人。
猜准年紀和性別,對大部分人來說不難,聲音特質已經透露出這些信息。
但猜對具體的容貌卻非常困難,人們只能回想腦海里有類似聲音的人,把他們的臉貼上去。

人的聲音和長相應該是分開的吧……
AI告訴我們:答案不對,有特定聲音的人,會有特定的長相。
最近,麻省理工大學的科學家開發出一款AI,它能通過幾秒鐘的音頻,還原出說話者的容貌,相似度非常高。

年齡、性別、種族、五官特徵、臉型、髮型、鬍鬚造型,這些它能會繪製出來……
這款AI叫作「Speech2Face」,名字說得很清楚,「從話到臉」。
科學家創造它的目的,是想知道人類能在多大程度上,通過一個人的聲音推斷出他的長相。

乍一聽上去,這像看相那樣玄學,但背後的道理其實很好理解。
人類說話靠的是振動聲帶,它是位於喉部的左右對稱的兩瓣肉。聲帶的長度和寬度是影響我們音調高或低的主要原因,因為男性的聲帶較女性更寬,所以音調更低。
聲帶振動後,聲音在我們的胸腔里嗡嗡作響,大部分從喉嚨里傳出去。
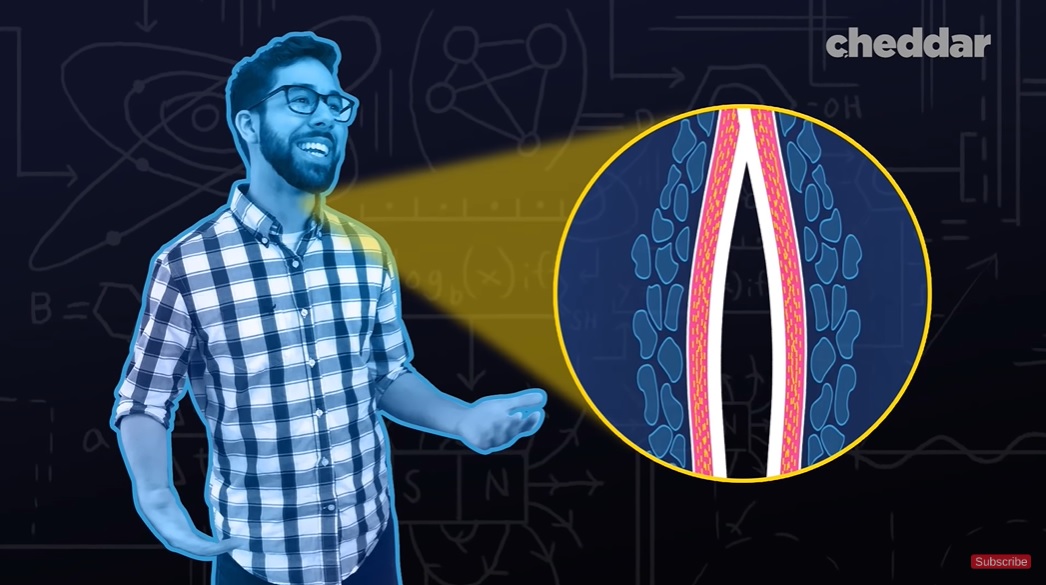
但這不是唯一的傳聲路徑,我們的臉部也充當着聲音的擴音器,顴骨、下巴、鼻子、嘴唇等都會振動,它們的厚度、結構不同,發出的聲音也不同。
電腦能捕捉到這些細微的聲音差別,繼而畫出說話者的面部特徵。
這就是AI工作的原理。

麻省理工的科學家們收集了油管上數百萬個視頻,裏面有十幾萬個人說話,他們將這些視頻輸入給Speech2Face。
Speech2Face會把視頻中人臉的特徵摘出來,製作出一張標準的正面照,這個照片基本等同對方的真人臉。
同時,它還會把聲音從聲波轉成聲譜圖,然後傳給人聲編碼器,找出其中的聲音特徵。
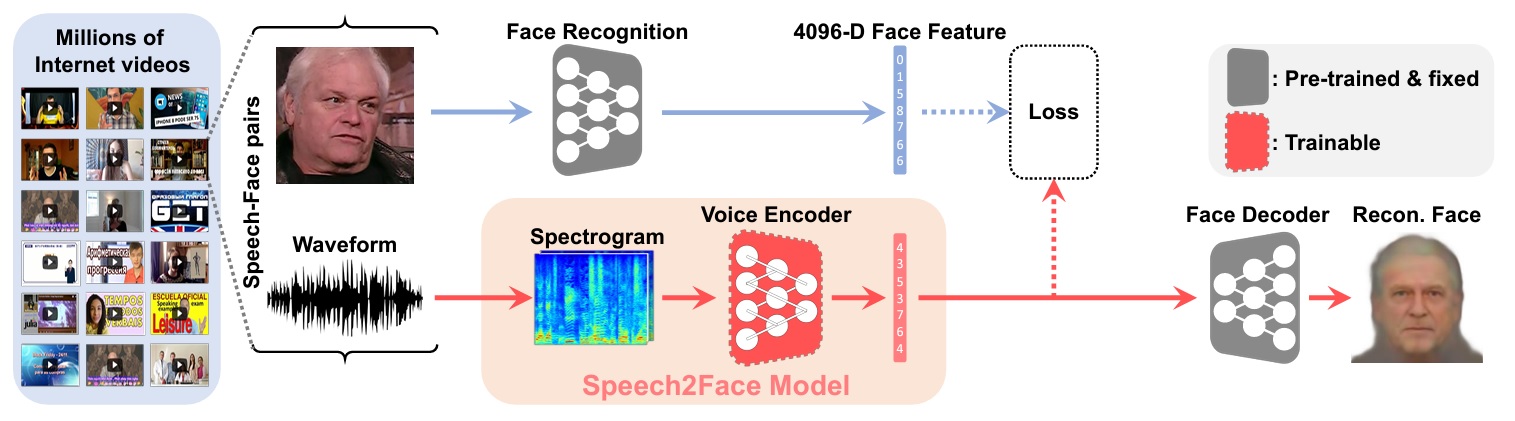
兩兩相對,Speech2Face就這樣學會聲音和相貌之間的關聯,不需要其他的信息。
在大量視頻的訓練下,它只需要聽3秒或6秒的音頻,就能畫出人臉。
比如,放美國情景喜劇《神煩警探》中男二霍爾特講笑話的音頻片段,Speech2Face會畫出下方右側的圖。

和飾演霍爾特的演員相比,右側的圖臉更寬和胖,但膚色和鼻子形狀與真人一樣,效果不錯。
其他測試對象還有白人老太太、非裔男子、拉美女孩和白人男性,
左邊的真人圖和右邊的AI圖對比,都挺像。
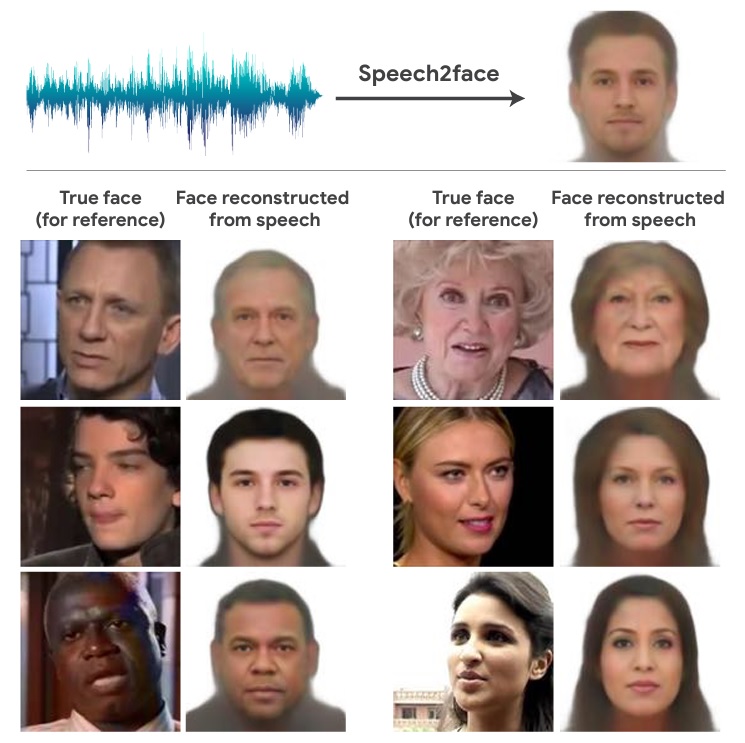
類似的對比圖在論文裏還有很多,下面這些圖的第一列是視頻截圖,第二列是電腦根據截圖轉換的正面照,第三列是AI根據聲音繪製的圖。

將第三列和前兩列對比,發現種族、性別、年齡、眉毛、髮型和發色基本都對。



為什麼眉毛和頭髮也能相似?它們又不隨聲音振動。



















{kind=link}