
由OpenAI自主開發的聊天應用ChatGPT風靡全球後,立即在全球範圍內掀起了大模型開發的熱潮。但準備參戰的玩家們很快便認清現實,這不過是一場由巨頭主宰的遊戲,其中的關鍵,就是能耗。
知名計算機專家吳軍的形容並不誇張——ChatGPT每訓練一次,相當於3000輛特斯拉的電動汽車,每輛跑到20萬英里,約32.19萬公里。而普通家用汽車年均行駛里程在1.5萬公里左右,ChatGPT每訓練一次,就相當於3000輛特斯拉在一個月走完了21年的路。
即便是對大模型躍躍欲試,準備「帶資入組」的大佬,也不得不掂量下:腰包里的銀兩,究竟夠花多久?
過去一年,OpenAI的總支出是5.44億美元。國盛證券估算,GPT-3的單次訓練成本就高達140萬美元,對於一些更大的LLM(大型語言模型),訓練成本介於200萬美元至1200萬美元之間。
其中,「大模型訓練成本中60%是電費,」華為AI首席科學家田奇在近日一場AI大模型技術論壇上強調,電力的降本增效已迫在眉睫。如果大模型普及,全球飛速運轉的伺服器,怕不會把地球燒了。
既然大模型訓練的成本中,電費佔主要部分,那麼究竟是哪些環節在耗電?又能如何優化?
大模型是「電老虎」
OpenAI曾在其《AIandCompute》分析報告中指出,自2012年以來,AI訓練應用的電力需求每3個月到4個月就會翻一倍。根據田奇給出的數據,AI算力在過去10年至少增長了40萬倍。其中,拉高AI大模型能耗的一大要因,就是參數訓練集的規模。
OpenAI行政總裁SamAltman在接受公開採訪時表示,GPT-3的參數量為1750億。最近發佈的GTP-4參數量是GTP-3的20倍,計算量是GTP-3的10倍。最快於2024年底發佈的GTP-5,參數量將達到GTP-3的100倍,計算量將飆升至200到400倍。
根據斯坦福人工智能研究所(HAI)發佈的《2023年人工智能指數報告》,訓練像OpenAI的GPT-3這樣的人工智能模型所需消耗的能量,足可以讓一個普通美國家庭用上數百年了。GPT-3是目前大模型中有據可查的第一大「電老虎」,耗電量高達1287兆瓦時。
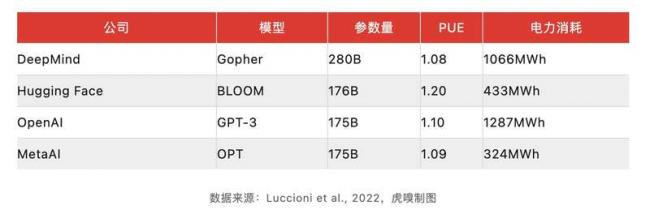
參數訓練集的規模,是拉高大模型能耗的主要因素。其中AI處理器和晶片,是產生能耗最主要的地方,一位信息和通信技術從業者告訴虎嗅,CPU和GPU的功耗通常占伺服器整機的80%。不過和普通伺服器750W到1200W的標準功耗相比,AI伺服器由於配置多個系統級晶片,在運行AI模型時會產生更多的能耗。
以英偉達DGX A100伺服器為例,搭載8顆A10080GB GPU,最大系統功耗達到6500W,外形尺寸為6U,考慮42U的標準機櫃,則單機櫃可放置7個DGX A100伺服器,對應功耗為45.5KW。
按照ChatGPT在今年1月日均1300萬的UV標準,OpenAI需要3萬多張A100 GPU,初始投入成本約為8億美元,折算下來的電費每天是5萬美元左右。
「如果大模型的使用者越來越多,為了保證時延,需要追加伺服器訂單,來提供更多的基礎算力。假設有10萬用戶的並發計算量,差不多要30萬到40萬張GPU才夠。」某頭部數據中心業務負責人推算道。
數據顯示,ChatGPT的總算力消耗約為3640PF-days,這需要七到八個投資規模30億、算力為500P的數據中心才能支撐運行。根據半導體行業資訊機構SemiAnalysis估算,未來如果讓ChatGPT承擔谷歌搜索的全部訪問量,至少也需要410萬張英偉達A100 GPU。

OpenAI訓練其模型所需的雲計算基礎設施規模是前所未有的,比業內任何人試圖構建的GPU算力集群都要龐大
目前,微軟在六十多個Azure數據中心部署了幾十萬張GPU,為ChatGPT提供超強算力。作為OpenAI最大的投資方,微軟拿到了雲計算基礎設施的獨家供應權,並開始下一代AI超級計算機的開發工作當中,數萬張英偉達A100 GPU以及新一代H100 GPU都將被導入其中。
前所未有的算力規模,連業內專家都在感慨,這是一件多麼瘋狂的事。
AI引發新技術革命
瘋狂的事,催生更瘋狂的想像力。
眼下,就連呼籲暫停大模型開發的馬斯克,也要打造「推特版的ChatGPT」了。
根據美國知名科技媒體Business Insider報道,馬斯克已經購買了一萬塊GPU,通過生成式的AI大模型和海量數據,強化推特的搜索功能並幫助其廣告業務重整旗鼓。
作為OpenAI的早期投資人,外界一直對馬斯克抵制AI發展的態度半信半疑。就在本月初,網絡上還有傳言稱馬斯克將在半年後打造比GPT4更強大的大模型。
更有傳言稱,馬斯克計劃通過SpaceX把超級計算機搬到太空上,目的是節約製冷和耗能。且不論這件事的真假,看起來倒是個好點子。
截圖來自網絡
打造太空數據中心,似乎能享有得天獨厚的資源稟賦:24小時天然低溫散熱,全年無限量太陽能,而且全部都免費。那麼這個絕妙的創意,到底靠不靠譜?
一位民營商業航天專家否定了這個想法,他告訴虎嗅,太空超低溫環境確實不假,但很多人忽略了一個基本的物理常識,那就是所有熱量的交換都是靠分子運動實現的。而太空環境趨近於真空,所含物質過於稀少,因此,「雖然溫度低,但是導熱慢,自然散熱條件其實遠不如地面。」
其次,目前衛星太陽能帆板的供電系統普遍功率只有1200W,無論是電力供應還是成本,地面光伏解決方案都有絕對的優勢。
另外,訓練大模型需要大量的數據輸入和輸出,這要求伺服器具備超高的網絡帶寬能力。太空信息基礎設施提供商艾可薩聯合創始人王瑋認為,數據中心作為網絡互聯底座,保證數據傳輸的穩定性和速率至關重要。但就目前來看,「即便消耗星鏈全部的帶寬,都未必都能保證大模型訓練所需的數據實時傳輸需求。」
當然,還有一些革命性的技術創新被ChatGPT帶火,中科創星創始合伙人米磊表示,最典型的就是光子技術。比如具備高算力、低能耗優勢的光電共封裝(CPO)技術。簡而言之就是將光器件和交換晶片封裝在一起,為暴漲的算力需求提供了一種高密度、高能效、低成本的高速互連解決方案。
米磊認為,本輪大模型領域的熱潮代表了「AI技術的發展進入了全新階段」。作為一種用光進行運算的晶片,其耗電量僅占同等級電子晶片的六分之一。隨着人工智能不斷發展,訓練、運行這些產品需要的算力水平也越來越高,行業對高速率、低能耗的光晶片也越發期待。
截至目前,中科創星在光電領域累計投資了超過150家企業。早在2016年米磊就提出,光是人工智能的基礎設施,光子是新一代信息技術基石的理念。「喊了這麼多年,冷門的技術終於被ChatGPT帶火了。」最近二級市場上光晶片相關股票的大漲也體現出了這一點。這種偶然性,在米磊看來是必然趨勢。
着眼於當下,降低AI模型整體能耗、節省電費開支的主要方式,依然是想辦法提高數據中心的散熱效率。中金公司認為,以液冷技術為代表的主動散熱技術有望憑藉優良的散熱性能被更多地採用。
相較於傳統的風冷系統,液冷系統直接將熱負荷傳遞至冷凍水系統中,製冷效率更高且佔地更小,能夠提升伺服器的使用效率及穩定性,滿足高功率密度機櫃的散熱要求。
例如英偉達HGX A100採用的直接晶片(Direct-to-Chip)冷卻技術,在機架內直接整合液冷散熱系統,取代傳統的風冷系統散熱,實測消耗的能源減少了約30%。而液冷數據中心的PUE(電源使用效率)能達到1.15,遠低於風冷的PUE1.6。
隨着大模型對算力的渴求,市場對高性能晶片的需求還將進一步提升。新思科技全球資深副總裁兼中國董事長葛群就曾表示,到2025年全球數據中心佔整個全球用電量將要提升到全球的20%。「因此,在全球最領先的科技公司中,最重要的一項技術方向就是如何能夠使他們的數據中心能耗降低,成本降低。」
早在7年前,作為全球EDA(電子設計自動化)和半導體IP領域龍頭的新思科技就啟動了一項叫做「高能效設計」的項目,將晶片的能效最大化。
這種能耗管理的邏輯是,數據中心有多塊晶片,每個晶片上有幾十億甚至上百億的電晶體,一個電晶體,相當於一個用電單位,以此推斷,一顆指甲蓋大小的晶片,就是一個規模龐大的能源網絡。如果能夠將每個電晶體的能耗優化,那麼最後的節能就能輻射到整個數據中心。
一位資深分析師人士坦言,市場大可不必對大模型的能耗問題過度擔憂。「很多人忽略了一個事實,那就是大模型對算力的需求未來必然會逐漸下降,這意味着能耗也會相應降低。」例如,微軟剛剛宣佈開源的DeepSpeed-Chat就充分印證了這一點。
據了解,DeepSpeed-Chat是基於微軟 DeepSpeed深度學習優化庫開發而成,具備訓練、強化推理等功能,並使用了RLHF(基於人類反饋的強化學習)技術,可將訓練速度提升15倍以上,算力成本大大降低。比如,僅憑單個 GPU就能支持一個130億參數的類ChatGPT模型,訓練時間也只需要1.25小時。
與此同時,該分析師補充說,未來算力的分佈結構一定會朝着分佈式、去中心化的方式演進,即訓練過程在雲端完成,在邊緣和端側重推理。「而不會像現在一樣,所有的壓力全部由超算中心承擔。」


















{kind=link}