全球科技業最大明星ChatGPT及背後的大模型混戰,意外地讓原本「需求下降」的晶片產業煥發新動力。
美股「七巨頭」蘋果、微軟、谷歌、亞馬遜、英偉達、臉書、特斯拉,全都是與晶片、AI相關的巨型科技公司,在過去一年股價市值飆升,全年漲幅最小的也達到50%,GPU霸主英偉達表現最為強勁,2023年市值增長239.2%,拉動納斯達克指數全年上漲44.2%。在美聯儲大幅加息的背景下,被稱為有史以來最奇怪的牛市。
這些高科技公司市值變化驚人,背後的關鍵邏輯是晶片業的技術進步,特別是GPU相關的技術革命。

黃仁勛在Computex2023展會上發表演講
過去一段時間,中國晶片業被美國針對,輿論更為關注手機SoC以及相關的製程工藝,比如7nm、5nm。華為麒麟9000S的問世,說明中國大陸突破了7nm SoC晶片的製造技術,形成了從設計、製造到商業的閉環。
不過,消費人群對GPU相關技術陌生,而恰恰在這方面中美相關產品在這方面的差距又非常明顯。英偉達、AMD這些矽谷巨頭還在不斷加速提升先進GPU性能,中國自主產品性能差距被拉到十倍以上。
面對美國步步收緊的先進晶片出口管制,中國的人工智能產業,會因為算力和相關晶片性能有限被「卡脖子」而落後嗎?我們可以從GPU技術的發展,英偉達這樣的晶片「巨無霸」的成長曆程,汲取到哪些可以借鑑的方法論?
01英偉達的成功是靠運氣嗎?

第一款GPU:英偉達GeForce256
1999年英偉達發佈GeForce256時正式提出Graphics Processing Unit的概念,中文翻譯過來即圖形處理單元。
GPU的狹義概念即顯卡——CPU無法處理屏幕上的圖像,需要專門的顯卡,早期有眾多設計、生產顯卡的公司。比如90年代頗有名氣的3dfx,其1995年推出的3D加速卡Voodoo,讓PC遊戲性能大增。《古墓麗影》、《雷神之錘》等遊戲讓Voodoo名聲大噪。1997年發佈的Voodoo2在3D顯卡技術競爭中更是獨孤求敗。時至今日,遊戲玩家依舊是高端顯卡的狂熱用戶群。
不過,Voodoo2並沒有讓3dfx一路領先。市面上的顯卡產品種類繁多,遊戲和3D應用的適配成為開發商最棘手的問題,微軟適時推出了DirectX,統一規範硬件、軟件廠商的設計,方便了開發。固執堅守自家生態的3dfx,面臨被遊戲、應用開發商孤立的局面。
與此同時,英偉達開始通過研發TNT系列產品來追趕3dfx,到第二代產品TNT2問世時已經完成對3dfx的性能超越,後者被動的捲入性能爭奪戰。英偉達推出革命性的GeForce256,在顯卡晶片上實現了原來由CPU負責的T&L(Transforming& Lighting,幾何光影轉換)能力後,3dfx計劃反擊,但產品連續跳票,客戶紛紛轉投英偉達。
激烈的爭奪戰當中,微軟成為壓死3dfx的最後一根稻草。
面對英偉達的挑戰,3dfx孤注一擲,決定用1.8億美元收購圖形晶片公司,爭取微軟Xbox遊戲機圖形晶片大單來挽救公司,但微軟選擇了英偉達。最終,陷入困境的3dfx被英偉達以7000萬美元和100萬股公司股票低價收購。
從1999年2月TNT2性能趕超,到1999年8月推出GeForce256,再到2000年底3dfx被收購,一家明星公司隕落之快,反映出了技術快速進步、尊重客戶的重要性,也反映出了競爭的殘酷性。
彼時,英偉達的勝利「基因」已經顯現,但沒人想像得到,這個「基因」價值如此巨大。在後來的GPU行業競爭中,廣大客戶的擁護、性能指標的快速疊代、各類應用算法的高效優化、穩定易用的軟件引擎接口、大公司的支持、設計與製造分離,成為IT硬件公司持續競爭獲勝的法寶。
PC高增長時代,英特爾、英偉達和AMD也是顯卡領域的核心玩家。
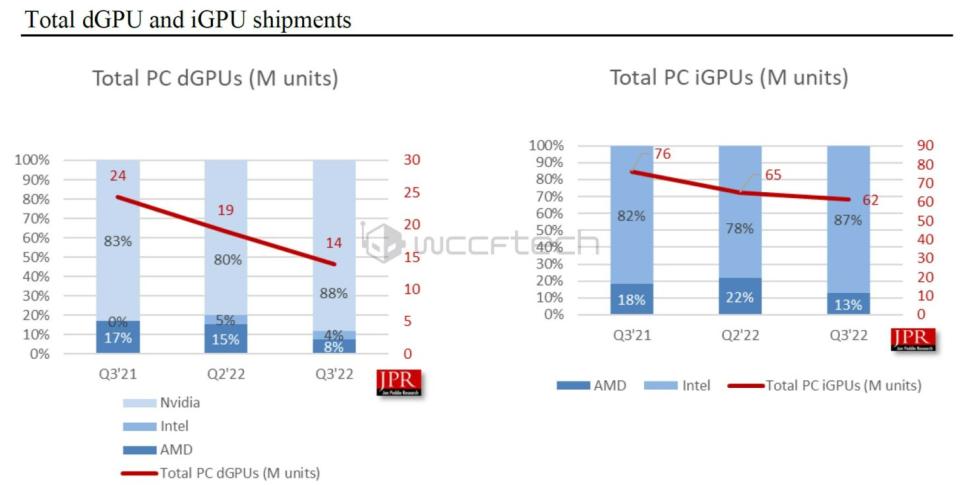
2021年Q3到2022年Q3,獨立顯卡與集成顯卡市場份額佔比,英偉達和英特爾分別佔據絕對領先的份額
英特爾走的是集成顯卡路線,直到2022年才推出獨立顯卡。AMD既有集成顯卡,也發展獨立顯卡,2006年54億美元收購了顯卡公司ATI,走CPU和GPU「雙路發展」的路線。在此之前的2004年,ATI開發的Radeon9700顯卡有1.1億個電晶體,在技術上首次領先英偉達,和微軟關係也更好,率先支持DirectX9.0,獲得了Xbox訂單。英偉達則專注開發獨立顯卡,市場份額高達80%以上。
02通用計算幫英偉達「開掛」
千禧年初期,一般用戶有集成顯卡就夠了,獨立顯卡需求以遊戲玩家為主,並非主流市場。而計算的邏輯,也以堆CPU的超算為代表,相比之下,GPU在計算方面的性能並不起眼。
2003年,GPU通用計算(GPGPU)概念被提出。之後多年英偉達幾乎是憑「一己之力」,將GPU的通用計算功能發揮到了難以想像的高度。GPU跳出單一的3D圖像顯示應用場景,在隨後的20年逐漸在神經網絡、科學計算、雲計算、AIGC、大語言模型等多個領域廣泛應用。
通用計算成為英偉達增長的新引擎,遊戲相關產品也發展很好,英偉達繼續在遊戲市場持續疊代GeForce系列產品,通過加入光線追蹤等高級功能,性能一直領先。英偉達精準劃分不同的SKU,適應需求差異化的用戶群,此舉也被稱為創始人黃仁勛的「刀法」。
但真正讓英偉達成為萬億美元市值傳奇公司的,是2009年推出的用於數據中心的Tesla系列產品,如V100、A00、H100、H200,將GPGPU的高密度並行計算功能指標不斷大幅提升。
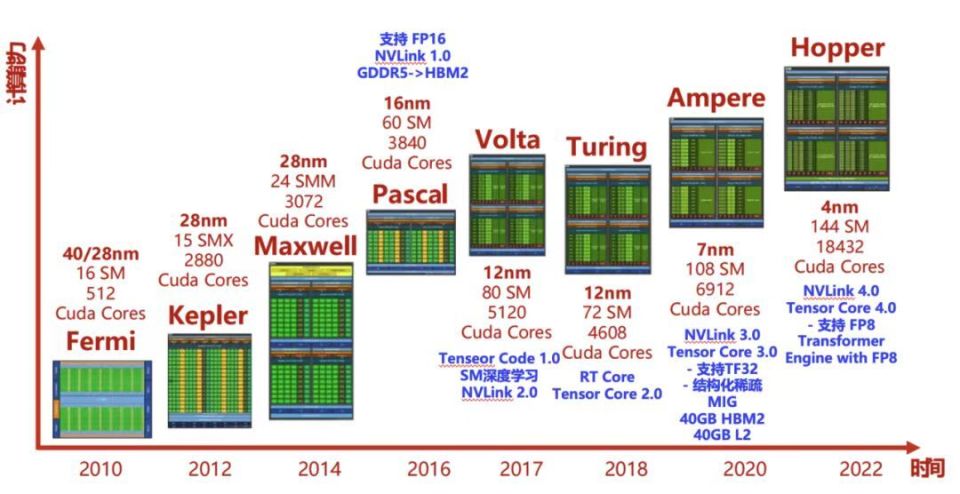
英偉達2010年開始推出的GPU架構及其對應的計算性能
英偉達「開掛」的黃金髮展時間,至今大約是15年,其動力是GPU架構不斷發展。這個過程中英偉達用科學家的名字對架構命名,以致敬科學先輩。H100和H200採用的Hopper架構,名稱來自Grace Hopper(格蕾絲·赫柏,計算機軟件工程專家,bug這個詞就是她在計算機繼電器上找出一隻小蟲)。
到目前為止,從英偉達的營收劃分來看,「數據中心」業務的營收佔比超過5成,成功超越「遊戲娛樂」業務,後者只佔3成多。另外還有不到10%聚焦「工業領域」,分別是主打高端圖形,用於設計、建築行業工業可視化的Quadro系列,以及主攻汽車自動駕駛領域的Orin系列。
總體來看,英偉達成為GPU霸主,主觀原因在於不斷的進行技術疊代,算法的優化、不斷響應客戶的差異化需求,以及大客戶的支持等。
單純以性能指標為例,以GPT-3應用評估算力,2023年的H100,在2021年的A100的基礎上,性能翻了11倍,H200則翻了18倍,將推出的B100性能又是H200的兩倍。期間儘管英偉達在「漲價」,但單位美元能完成的訓練工作量也大幅提升。
客觀上,英偉達的勝利和深度學習的流行關係很大,其針對人工智能應用深度優化的CUDA(Compute Unified Device Architecture)生態則是英偉達致勝的基石——它擁有上萬名研發人員,開發者可直接使用CUDA開發庫,不需要自行優化GPU相關代碼,讓英偉達擁有了用戶慣性,軟件、硬件兩手都很硬。可以說,在人工智能軟件生態里,英偉達就相當於PC軟件生態里的微軟。
英偉達市值衝破萬億美元,還有一個罕見現象助推——時間優勢——競爭對手就算能趕上英偉達,總要遲一些時間。
對於佈局人工智能領域的巨頭來說,時間是重要的考量因素之一,影響其佈局的有幾點:
一是英偉達競爭對手研發生產出對標產品要時間;
二是應用GPU的公司進行軟硬件適配也要不短時間,而英偉達軟件生態成熟能快速上手;
三是一些大型訓練需要不短的時間,如果硬件性能與軟件優化稍差一些,時間代價就會難以承受。
在ChatGPT爆火,AI硬件需求出乎預料地爆發增長的背景下,出現了「搶購」英偉達高性能GPU的現象。英偉達開出一塊GPU幾萬美元的高價,各大公司豪氣地以幾萬、十萬計的數量「買卡」。
例如,印度數據中心運營商Yotta訂購了16000個H100,到貨期排到2024年7月了,近日又花5億美元追訂16000個H100和GH200,2025年3月前到貨。社交媒體巨頭Meta為了開發AGI(通用人工智能),2024剛開年就拋出了35萬塊H100的訂單炸場,加上已購的囤積60萬塊H100的超級算力。成本3000美元的H100賣3萬美元,這一單的利潤就超乎想像。
正是這些難以置信的超大訂單,將英偉達股價頂上了600美元,市值突破1.5萬億美元(截至當地時間2月1日美股收盤,英偉達市值1.56萬億美元,約合人民幣11.16萬億元)。而市場需求的「好消息」似乎還沒完,如AI PC又成為熱門,人人都要高性能GPU讓自己的PC變聰明。
03 GPU的超強算力來自哪裏?
從現在眼光看,在架構上GPU的加速性能比CPU更出眾,提升指標的辦法更多,所以性能一直在快速進步。相比之下,CPU的計算速度提升已經放緩,更多是移動應用的功耗指標提升。一些指標進步還是靠與GPU集成實現的,比如蘋果用於PC的M1、M2、M3系列晶片,集成顯卡的性能飛速進步,M3跑出M1的圖形性能只需一半功耗,峰值性能提升65%。
從硬件來看,GPU有兩大類部件,一類是多個用於執行並行計算的計算單元,一類是存儲數據的顯存。
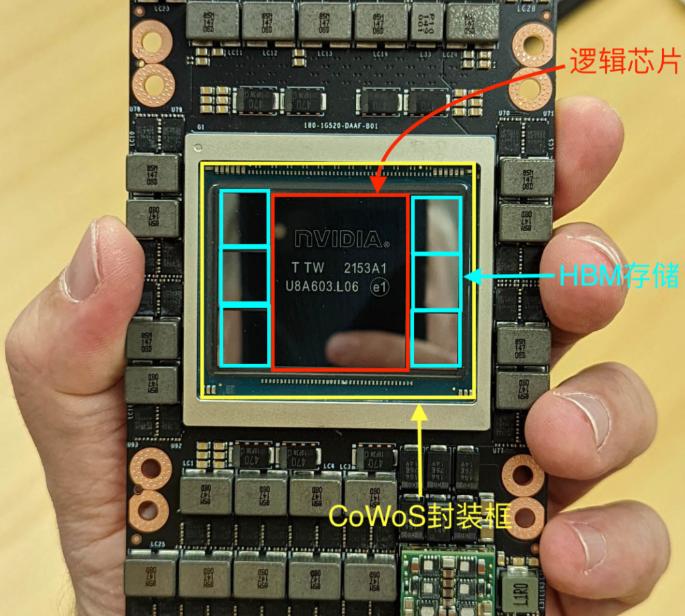
英偉達 H100 GPU SXM5模組,中間為1顆Hopper GPU邏輯計算晶片+6顆HDM內存
比如H100,有一顆英偉達設計的邏輯計算晶片,以及六顆各16GB的HBM3存儲晶片(如上圖),採用台積電的CoWoS(Chip on Wafer,Wafer on Substrate)先進封裝技術緊密連接組成一整塊晶片。
通俗的理解,GPU的超級計算能力源於成千上萬個計算單元,它的功能各異,要互相配合完成多種多樣的圖形處理、AI計算任務,且需要分級管理。相當於很多個CPU同時運行,儘管單個計算單元能力有限,疊加起來性能就會大幅躍升。不過,GPU的計算單元與CPU里的4核、8核多線程並行概念不同。
計算單元數量越來越多、功能越來越複雜高級,這正是英偉達從Fermi架構到Hopper架構不斷優化的動力。
從計算意義上看,處於最頂層是整個GPU,它包含若干個次級的圖形處理簇(GPC,Graphics Processing Cluster),某個圖形處理簇處理完的數據,會通過Crossbar連接,分配給另外的圖形處理簇繼續處理。一個圖形處理簇又包含數個流式多處理器(SM,Stream Multiprocessor)。
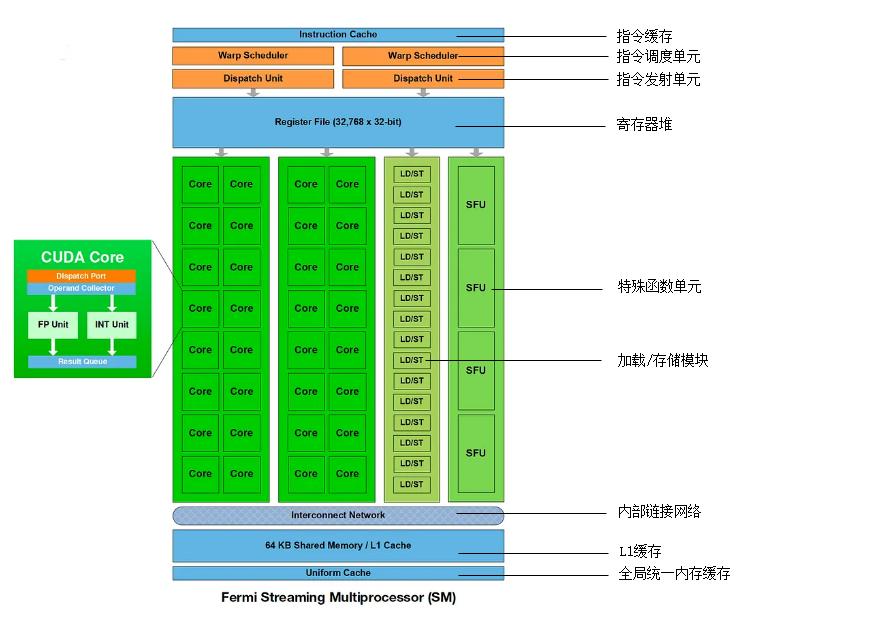
流式多處理器架構細節
以Fermi架構下單個流式多處理器為例,裡面包含了多種部件,最顯眼的是32個Core(又叫做CUDA Core,如上圖左邊部分所示),也就是「流處理器」運算核心。Fermi架構的單個圖形處理簇能高效完成一些指定的任務,成為一個引擎,如PolyMorph Engine多邊形變形引擎,可以大幅度提升幾何圖形的處理能力。
//註:一般大型遊戲的一幀畫面包含數百萬個幾何多邊形,CG動畫中一幀畫面中的多邊形更是可以達到數億個。

完整的英偉達Fermi架構示意圖
如上圖所示,完整的Fermi架構有4個圖形處理簇、16個流式多處理器,總計512個CUDA Core。它們的特點是對向量進行處理,一個GPU時鐘周期執行一次乘法、加法等操作,只要數據組織成向量就能加速。概括下來,CUDA Core的個數直接決定了GPU的常規處理能力。
隨着深度學習興起,矩陣和卷積運算在計算任務中的比例急劇上升。CUDA Core可以做矩陣和卷積,但單步能力有限,加速需要多個CUDA Core並行操作。從2017年的Volta架構開始,英偉達引入了Tensor Core來特別處理矩陣和卷積,效率進一步優化。在深度學習最常見的GEMM矩陣乘法中,Tensor Core一個時鐘周期可以完成兩個4*4*4的FP16浮點矩陣乘法,拼成一個FP32的矩陣結果,這提供了10多倍的效率加速。
總結下來,GPU的處理能力由CUDA Core和Tensor Core的數量所決定。公開資料顯示,H100的SXM5版本有132組流式多處理器,有16896個FP32 CUDA Core、528個Tensor Core。
//註:FP32、FP16代表單精度浮點數,可以用64bit、3bit、16bit、8bit來表示,分別稱為FP64、FP32、FP16、FP8。位數少,運算部件的成本低、性能高,但是數據精度會下降。在AI應用中,對精度不太敏感,大量係數數值都是0,可以選用位數少的浮點數來加速,比如FP8。英偉達發佈的Transformer Engine,利用FP8的加速特性,優化了Tensor Core算子,很好地支持了大模型訓練。
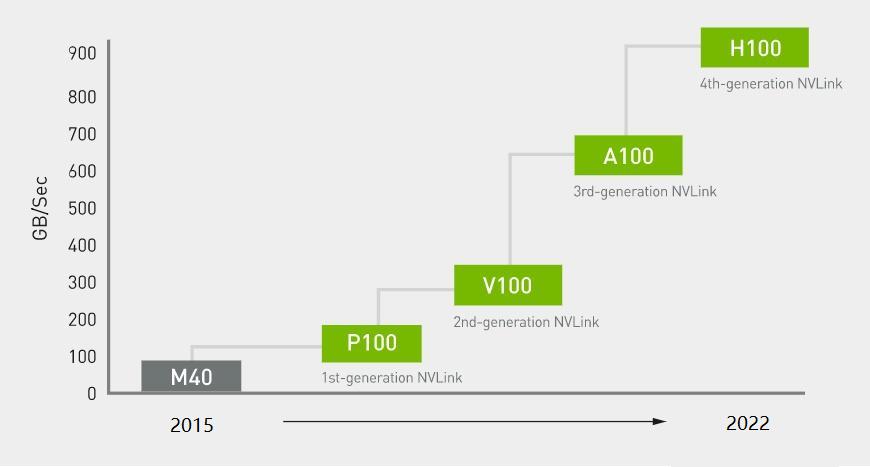
英偉達旗下主要產品的傳輸帶寬,基於第四代NVLink的H100,傳輸速率達到900GB/s
除了大量的計算單元,影響GPU硬件性能的另一個重要指標是傳輸通道帶寬。
過去,數據主要通過PCIE數據通道在主機與GPU之間通信,如PCIE3.0 x16的帶寬是16GB/S。使用GPU進行計算之後,顯卡之間也要傳輸數據,英偉達開發了專門的NVLink傳輸通道連接顯卡,帶寬不斷提升,H100的4代NVLink已經是900GB/S,是基於PCIE傳輸帶寬的10倍以上。
以上關於計算單元,CUDA Core和Tensor Core數量以及傳輸帶寬的案例,都是在強調,GPU強大的算力來源於諸多方面,在設計上可優化空間大,具體則包括顯存大小、顯存速度、緩存管理、數據通道、Core數量、單Core性能、數值精度、並行編程優化等等。
甚至在製造封裝環節,比如納米製程提升、先進封裝工藝研發,對於英偉達自身和後來的追趕者,都有參與的空間,可以改進的環節遠遠超過CPU。目前,如CoWoS先進封裝,要靠台積電的技術和產能。先進封裝產能與訂單數據,決定了高性能GPU出貨量,非官方的數據顯示,2024年台積電的CoWoS產能大概在每月2-3萬片左右,而且產能還要分給蘋果。
04巨頭自研GPU還有機會嗎?
從絕對的水平來說,英偉達GPU技術並非遙不可及,作為對手的AMD就追的很激烈。
AMD推出的MI300,官方稱部署GPT-4的性能超H100達到25%。對此,英偉達回應,應該以雙方均優化之後的性能指標進行對比才算公平。在這方面,不少公司在規劃自研或者已有針對特定任務進行優化的GPU產品。例如谷歌就自研了TPU,有能力給特定計算任務從設計到應用一條龍優化,定製適合的硬件。近日,OpenAI也對外釋放消息,稱英偉達GPU成本太高,計劃下場自研。
從技術角度,研發GPU是在大公司能力範圍之內,美國IT大公司都有不錯的晶片設計能力,七巨頭都是晶片設計巨頭,組織團隊設計高性能GPU不是問題。
更多的問題來自成本——GPU設計與應用的環節非常複雜,如果把各環節都做好,優化空間極大,也可以獲得更好的計算性能,但如果哪個環節做得不好,性能就會大打折扣,而性能非常關鍵,關乎的不僅僅是幾塊GPU,可能需要幾萬塊、幾十萬塊,數十億美元的成本直接決定了能夠下場自研的企業數量。
相比之下,英偉達的具備先發優勢,整個應用生態和研發流程諸多環節都很順暢,還在不斷地提升性能。即便競爭對手在遊戲渲染效果、大模型訓練效率一路追趕,但也只是追平了上一代產品。如果GPU的性能還能繼續高速提升,英偉達的霸主地位不會動搖,合理預期它會一直在市場技術指標、市場份額上大幅領先。
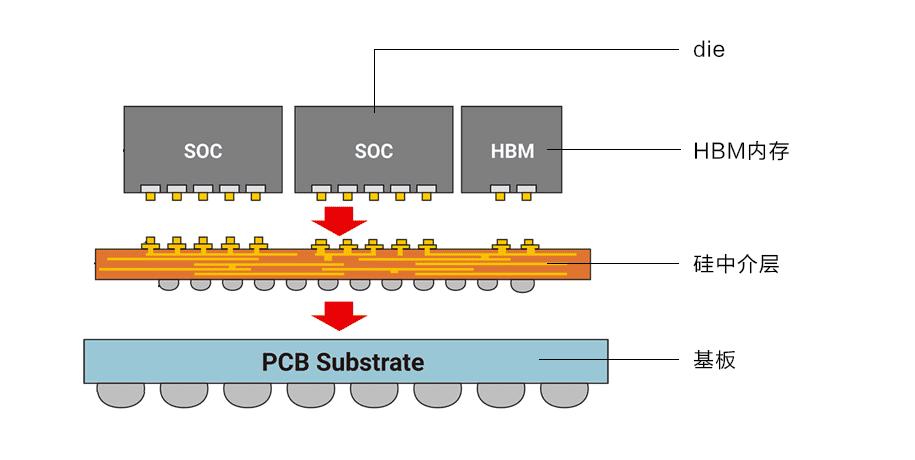
台積電CoWoS2.5D封裝示意圖
另外,由於目前台積電的CoWoS等先進封裝等製造技術還在進步,各種部件還沒有像晶片納米製程那樣受到物理限制,GPU架構還能不斷升級,流式多處理器與Core的數量還能不斷增加。
英偉達的優勢明顯,但並不代表對手沒有機會,核心的問題在於產能——搶購英偉達GPU都要排到一年以後才到貨,有足夠GPU技術能力的公司也會有市場,比如AMD就是替代選項之一,而矽谷的科技巨頭在供應鏈的建設上,也習慣培養後備力量避免被單一合作夥伴「卡脖子」。
相比之下,中國市場的情況較為特殊,由於受到出口管制的影響,有大量潛在的空白市場待填補。據了解,一些公司目前也在藉助大模型訓練,進行國產GPU的適配,半年左右的開發,可以實現A100晶片60%-70%的性能。
與此同時,大公司在相關出口管制條例出來之前,已經有大量相關算力的儲備,在這種情況下,培育國產GPU生態更加任重道遠。
從整個晶片設計市場來說,CPU也在進步,尤其是通過先進封裝集成GPU,比如蘋果的M系列晶片、高通的Snapdragon X Elite,這說明高性能晶片的潛力還很大。只是從大眾需求的角度看,PC、手機的CPU晶片性能已經存在過剩,沒有太多市場想像力,而相反,就與AI的大規模應用,GPU大眾應用的想像力是開放的。比如在圍棋AI領域,GPU算力高,圍棋AI的水平就高,GPU性能成了圍棋AI弱機、強機的判定者。
可以想像,自己的AI助手有多聰明,很可能是配備的GPU性能決定的,那GPU的市場前景還望不到盡頭。
這家最好!股市開戶分批買入大盤股指基金
:比爾蓋茨,美股動態


















{kind=link}