
要是蘋果Vision Pro頭顯加上AI助手,有多強?
南洋理工大學與微軟雷蒙德研究所帶來一個震撼概念演示。
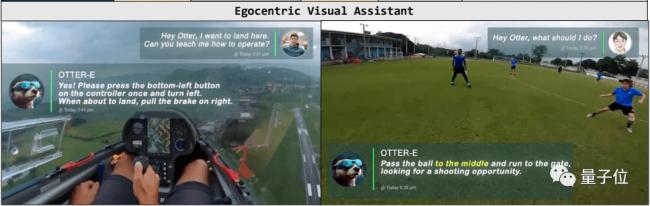
人在飛機上,不知道怎麼降落?帶上頭顯把畫面傳給AI,就能一步一步你操作。
這個多模態AI助手名叫Otter(水獺),以視頻為輸入,能完成多模態感知、推理、和上下文學習,也經過專門的遵循指令訓練。
更貼近生活一些的場景,在麻將桌上,Otter分分鐘教你胡幾次大的。
而當你鍛煉身體時,Otter可以充當你的計數器。
調酒師小哥忘記配方時,也能分分鐘化解尷尬。
Otter一共支持八種語言,中文也包括在內。
訓練過程中,團隊專門使用了適用於AR頭顯的第一視角視頻,宣傳上也明示就是為蘋果頭顯準備的。




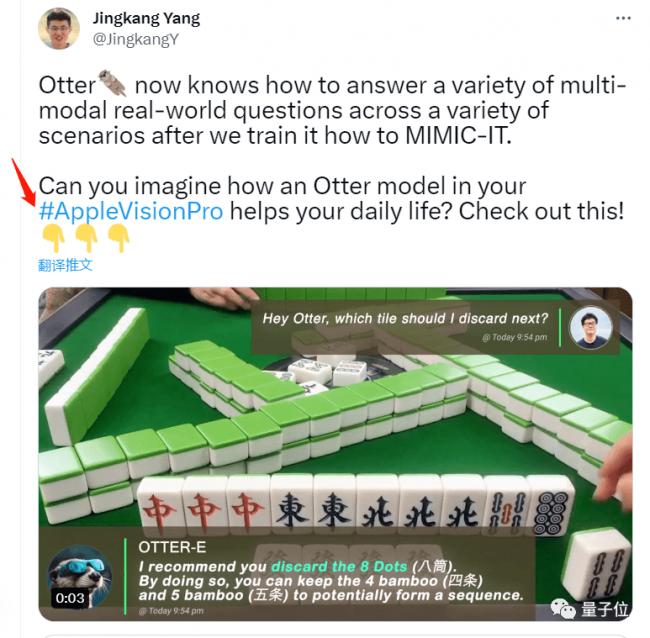
不過也有網友發現了華點。
結果,Otter在各測試項目上的平均成績比傳統的MiniGPT-4、OpenFlamingo等傳統模型高出十餘個百分點。
如何實現
其中核心的視覺模塊是基於改進版本的LLaVA進行訓練的。
Otter整體的工作流程大概是這樣的:
首先要對視覺信息進行處理,並結合系統信息生成prompt。
生成好的prompt會被傳遞給ChatGPT,得到指令-回應數據。
這樣得到的答案再經過一步篩選器篩選之後,由ChatGPT翻譯成用戶選擇的語言並輸出。
在主線流程之外,團隊還引入了冷啟動機制,用於發現數據庫中可用的情景實例。
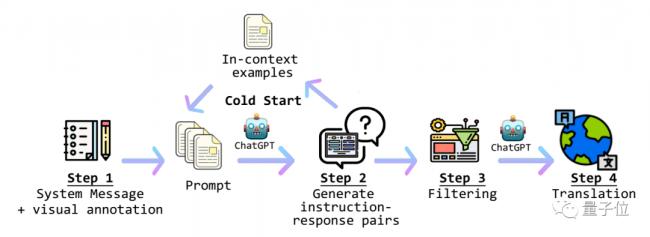
接下來,讓我們看一下當中最關鍵的環節,也就是視覺信息的解釋。
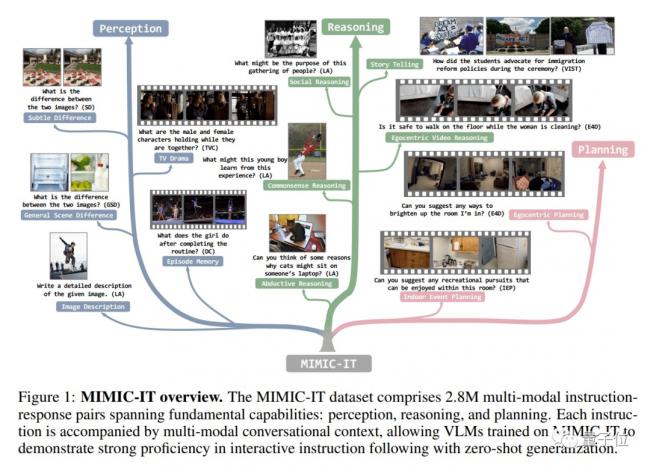
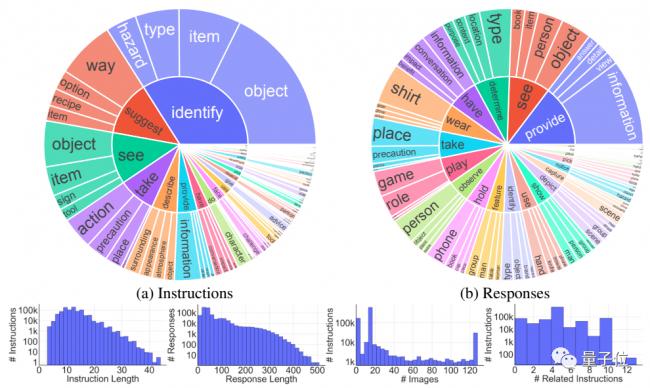
為了訓練Otter,研究團隊專門提出了Mult I- Modal In- ContextInstruction Tuning(多模式場景下的指令調整)數據集。
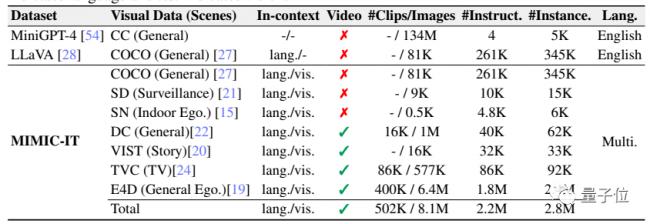
MIMIC-IT涵蓋了大量的現實生活場景,而且不同於傳統的LLaVa等只有一張圖片和語言描述的數據集,MIMIC-IT包含多種模式。

第一步是對場景化信息的學習,這一部中使用的是經過調整的LLaVA數據集。
對數據集中的每個指令-相應組,團隊都基於文字或圖片相似性為其檢索了是個場景化實例。
為了更好地適應真實世界,下一步的訓練主要是讓模型發現圖像之間的差別。
而這些差別又被分為了一般差別和微小差別兩種類型。
對於一般差別,通過prompt讓ChatGPT進行圖像分析和物體檢測生成注釋。
而對於微小差別,則使用自然語言描述作為注釋。
擁有了發現差別的能力之後,就要讓模型嘗試着「講故事」了。
由於圖像注釋無法直觀反映時間線等要素,研究團隊讓ChatGPT充當觀眾並回答一系列問題。
每一個場景之中都包含圖像和對應的指令-響應組。
為了擴展模型的視野,研究團隊還讓它學習了包含大量說明的長視頻片段。
說明信息包括視頻內容、人的動作和行為、事件發生的順序和因果關係等。
為了增強模型的社交推理能力和對人物複雜動態行為的理解,研究團隊最後把電視劇作為了訓練材料。
介紹完一般場景,我們再來看看第一人稱場景又是如何分析的。
第一人稱場景既包括視覺上直觀看到的內容,也包括觀察者的內心感受。
研究團隊從ScanNetv2數據集中搜集了一些場景並進行採樣,轉化為多個第一人稱視角的二維視覺信息。
研究團隊還讓ChatGPT基於隱式設定的人物性格指導人類的行為,為模型生成訓練數據。
作者簡介
研究團隊的成員主要來自南洋理工大學S實驗室,第一作者是該實驗室的博士生李博。
2017年,李博獲得中國大學生編程比賽銀獎。
2018年至今,李博先後在滴滴、英偉達、微軟等機構先後從事研究工作。
李博的導師劉子緯助理教授是本文的通訊作者。
此外,微軟雷蒙德研究院首席研究員Chunyuan Li也參與了本項目。
Otter的介紹視頻在B站也有發佈。

















{kind=link}