於2022年底問世的ChatGPT,震撼了互聯網。不由得使人聯想起2016年初的AlphaGo,挑戰人類頂級圍棋大師李世石的故事。我在2017年出版的一本概率科普書中【1】,對當年人工智能的狀況稍有描述,那算是AI的第二次革命,深度機器學習和自然語言處理(NLP)剛起步。沒想到短短几年過去,第三次AI浪潮滾滾而來,基本搞定了自然語言的理解和生成難題,以 ChatGPT發佈為里程碑,開闢了人機自然交流的新紀元。
人工智能(AI)的想法由來已久,英國數學家艾倫·圖靈,不僅僅是計算機之父,也設計了著名的圖靈試驗,開啟了人工智能的大門。如今,人工智能的應用已滲入到我們的日常生活中。它的成功崛起,來源於計算機的飛速發展、雲計算的興起、大數據時代的來臨,等等。其中,與大數據有關的數學基礎主要是概率論。因此,此文就聊聊ChatGPT與概率相關的一個方面,更具體來說,是與幾百年前的一個人名有關:貝葉斯。
概率論和貝葉斯
針對概率論,有法國牛頓之稱的拉普拉斯(1749年-1827年)曾說:
「這門源自賭博機運之科學,必將成為人類知識中最重要的一部分,生活中大多數問題,都將只是概率的問題。」
兩百多年之後的當今文明社會,證實了拉普拉斯的預言。這個世界充滿了不確定性,處處是概率,萬物皆隨機。無需抽象定義,概率論的基本直觀概念早已滲透到人們的工作和生活當中,小到人人都可以買到的彩票,大到星辰宇宙,複雜到計算機和人工智能,都與概率密切相關。
那麼,貝葉斯又是誰呢?
托馬斯·貝葉斯(Thomas Bayes,1701年-1761年),是18世紀的一位英國數學家、統計學家,他曾經是個牧師。不過他「生前籍籍無名,死後眾人崇拜」,在當代科技界「紅」了起來,原因歸結於以他命名的著名的貝葉斯定理。這個定理不僅在歷史上促成了貝葉斯學派的發展,現在又被廣泛應用於與人工智能密切相關的機器學習中【2】。
貝葉斯做了些什麼?當年,他研究一個「白球黑球」的概率問題。概率問題可以正向計算,也能反推回去。例如,盒子裏有10個球,黑白兩種顏色。如果我們知道10個球中5白5黑,那麼,如果我問你,從中隨機取出一個球,這個球是黑球的概率是多大?問題不難回答,當然是50%!如果10個球是6白4黑呢?取出一個球為黑的概率應該是40%。再考慮複雜一點的情形:如果10個球中2白8黑,現在隨機取2個球,得到1黑1白的概率是多少呢?10個球取出2個的可能性總數為10*9=90種,1黑1白的情況有16種,所求概率為16/90,約等於17.5%。因此,只需進行一些簡單的排列組合運算,我們可以在10個球的各種分佈情形下,計算取出n個球,其中m個是黑球的概率。這些都是正向計算概率的例子。
不過,當年的貝葉斯更感興趣的是反過來的「逆概率問題」:假設我們預先並不知道盒子裏黑球白球數目的比例,只知道總共是10個球,那麼,比如說,我隨機地拿出3個球,發現是2黑1白。逆概率問題則是要從這個試驗樣本(2黑1白),猜測盒子裏白球黑球的比例。
也可以從最簡單的拋硬幣試驗來說明「逆概率」問題。假設我們不知道硬幣是不是兩面公平的,也就是說,不了解這枚硬幣的物理偏向性,這時候,得到正面的概率p不一定等於50%。那麼,逆概率問題便是企圖從某個(或數個)試驗樣本來猜測p的數值。
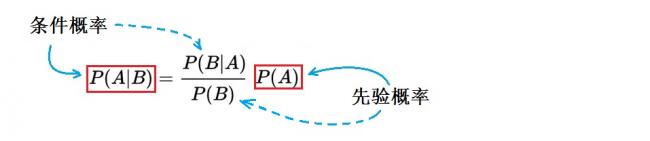
為了解決逆概率問題,貝葉斯在他的論文中提供了一種方法,即貝葉斯定理:
P(A|B)=(P(B|A)* P(A))/ P(B)(1)
這兒,A、B是兩個隨機事件,P(A)是A發生的概率;P(B)是B發生的概率。P(A|B)、P(B|A),稱為條件概率:P(A|B)是在B發生的情況(條件)下A發生的概率;P(B|A)是在A發生的情況下B發生的概率。
應用貝葉斯定理的例子
可以從兩個角度來解讀貝葉斯定理:一是「表述了兩個隨機變量A和B的相互影響」;二是「如何修正先驗概率而得到後驗概率」,以下分別舉例予以說明。
首先,初略地說,貝葉斯定理(1)涉及了兩個隨機變量A和B,表示兩個條件概率P(A|B)和P(B|A)之間的關係。
例1:某小城一月份治安不太好,30天內發生入室搶劫案6起。警察局有一個警報器,有事發生時便會拉響,包括火災、暴風雨等天災,及偷盜、強姦一類的人禍。一月份時,警報器每天都響。並且,從過去的經驗,如果有居民遭入室搶劫時,警報器響的概率是0.85。現在人們又聽到了警報聲,那麼,這次響聲代表入室搶劫的概率是多少呢?
分析一下這個問題。A:入室搶劫;B:拉警報。然後,我們已知(一月份):
入室搶劫的概率P(A)=6/30=0.2;拉警報的概率P(B)=30/30=1;P(B|A)=入室搶劫時拉警報的概率=0.85。
所以,根據公式(1),代入已知的3個概率,計算得到 P(A|B)=(0.85*0.2/1)=0.17。
也就是說,這次「警報響的原因是有人入室搶劫」的概率是百分之十七。
下面舉例說明如何用貝葉斯定理,從「先驗概率」計算「後驗概率」。首先將(1)改寫為如下樣子:
(2)
用一句話來概括(2),它說的是:利用B發生帶來的新信息,可以修改當B未發生時A的「先驗概率」P(A),從而得到B發生(或存在)時,A的「後驗概率」,即P(A|B)。
首先用美國心理學家,2002年諾貝爾經濟獎得主丹尼爾·卡尼曼舉的一個例子簡單說明。
例2:某城市有兩種顏色(藍綠)的出租車:藍車和綠車的比率是15:85。某日某輛出租車夜間肇事後逃逸,但當時正好有一位目擊證人,這位目擊者認定肇事的出租車是藍色的。但是,他「目擊的可信度」如何呢?公安人員經過在相同環境下對該目擊者進行「藍綠」測試而得到:80%的情況下識別正確,20%的情況不正確,問題是計算肇事之車是藍色的幾率。
假設A=車為藍色、B=目擊藍色。首先我們考慮藍綠出租車的基本比例(15:85)。也就是說,在沒有目擊證人的情況下,肇事之車是藍色的幾率為15%,這是「A=藍車肇事」的先驗概率P(A)=15%。
現在,有了一位目擊者,便改變了事件A出現的概率。目擊者看到車是「藍」色的。不過,他的目擊能力也要打折扣,只有80%的準確率,即也是一個隨機事件(記為B)。我們的問題是要求出在有該目擊證人「看到藍車」的條件下肇事車「真正是藍色」的概率,即條件概率P(A|B)。後者應該大於先驗概率15%,因為目擊者看到「藍車」。如何修正先驗概率?需要計算P(B|A)和P(B)。
因為P(B|A)是在「車為藍色」的條件下「目擊藍色」的概率,即P(B|A)=80%。概率P(B)的計算麻煩一點。P(B)指的是目擊證人看到一輛車為藍色的概率,應該等於兩種情況的概率相加:一種是車為藍色,辨認也正確;另一種是車為綠,錯看成藍。
所以:P(B)=15%×80%+85%×20%=29%
從貝葉斯公式:
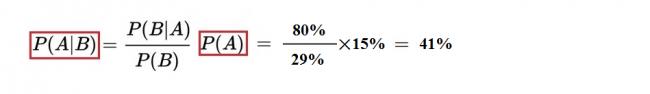
可以算出在有目擊證人情況下肇事車輛是藍色的幾率=41%。由結果可見,被修正後的「肇事車輛為藍色」的條件概率41%,大於先驗概率15%很多。
例3:公式(2)中,「先驗」和「後驗」的定義是一種「約定俗成」,是相對而言的,前一次算出的後驗概率,可作為後一次的先驗概率,再與新的觀察數據相結合,得到新的後驗概率。因此,運用貝葉斯公式,可以對某種未知的不確定性逐次修正概率模型並得到最終的客觀結果。
或者變個說法,有時也可以說,觀察者根據貝葉斯公式和不斷增加的數據,可能修正自己對某個事件的主觀「信任度」。
以拋硬幣為例,一般認為硬幣是「公平」的。但是,造假的情況太多,結果需要要靠數據說話。
比如說,設命題A為:「這是一個公平硬幣」,觀測者對此命題的信任度用P(A)表示。如果P(A)=1,表示觀測者堅信這個硬幣是「正反」公平的;P(A)越小,觀測者對硬幣公平的信任度越低;如果P(A)=0,說明觀測者堅信這個硬幣不公平,比如說,是一個造假的、兩面都標誌為「正面」的「正正」硬幣。如果用B表示命題「這是一個正正硬幣」的話,P(B)=1- P(A)。
下面我們看看如何根據貝葉斯公式來更新觀察者的「信任度」模型P(A)。
首先,他假設一個「先驗信任度」,比如P(A)=0.9,0.9接近1,說明他比較偏向於相信這個硬幣是公平的。然後,拋硬幣1次,得到「正Head」,他根據貝葉斯公式,將P(A)更新為P(A|H):

更新後的後驗概率P(A|H)=0.82,然後,再拋一次,又得到正面(H),兩次正面後新的更新值是P(A|HH)=0.69,三次正面後的更新值是P(A|HHH)=0.53。如此拋下去,如果4次接連都得到正面,新的更新值是P(A|HHHH)=0.36。這時候,這位觀察者對這枚硬幣是公平硬幣的信任度降低了很多,從信任度降到0.5開始,他就已經懷疑這個硬幣的公平性,接連4個正面後,他更偏向於認為該硬幣很可能是一枚兩面都是正面的假幣!
從上面幾個例子,我們初步了解了貝葉斯定理及其簡單應用。
貝葉斯定理的意義
貝葉斯定理是貝葉斯對概率論和統計學作出的最大貢獻,但在當年,貝葉斯的「逆向概率」研究和導出的貝葉斯定理看起來平淡無奇,未引人注意,貝葉斯也名不見經傳。如今看來完全不應該是這樣,貝葉斯公式的重要意義,是如例3所示的那種探知未知概率的方法。人們首先有一個先驗猜測,然後結合觀測數據,修正先驗,得到更為合理的後驗概率。這就是說,當你不能準確知悉某個事物本質時,你可以依靠經驗去對未知世界的狀態步步逼近,從而判斷其本質屬性。實際上,它的思想之深刻遠出一般人所能認知,也許貝葉斯自己生前對此也認識不足。因為如此重要的成果,他生前卻並未發表,是他死後的1763年,才由朋友發表的。後來,拉普拉斯證明了貝葉斯定理的更普遍的版本,並將之用於天體力學和醫學統計中。如今,貝葉斯定理更是當今人工智能中常用的機器學習之基礎框架【3】。
貝葉斯定理與當時的經典統計學相悖,甚至顯得有些「不科學」。因此它多年來一直被雪藏,不受科學家待見。從上一節例3可見,貝葉斯定理的應用方法是建立在主觀判斷的基礎上,先主觀猜測一個值,然後根據經驗事實不斷地修正,最後得到客觀世界的本質。實際上,這正是科學的方法,也是人類從兒童開始,認知世界(學習)的方法。所以可以說,近年來人工智能研究的興旺發達,關鍵之一是來自於經典計算技術和概率統計的「聯姻」。而其中的貝葉斯公式概括了人們學習過程的原則,如果配合上大數據的訓練,便有可能更確切地模擬人腦,教會機器「學習」,便能加速AI的進展。從目前情況看,也正是如此。
機器如何學習?
教機器學習,學些什麼呢?實際上就是要學會如何處理數據,這也是大人教孩子學會的東西:從感官得到的大量數據中挖掘出有用的信息來。如果用數學的語言來敘述,就是從數據中建模,抽象出模型的參數【4】。
機器學習的任務,包括了「回歸」、「分類」、等主要功能。回歸是統計中常用的方法,目的是求解模型的參數,以便「回歸」事物的本來面目。分類也是機器學習中的重要內容。將事物「分門別類」,也是人類從嬰兒開始,對世界認知的第一步。媽媽教給孩子:這是狗,那是貓。這種學習方法屬於「分類」,是在媽媽的指導下進行的「監督」學習。學習也可以是「無監督」的,比如說,孩子們看到了「天上飛的鳥、飛機」等,也看到了「水中游的魚、潛艇」等,很自然地自己就能將這些事物分成「飛物」和「游物」兩大類。
貝葉斯公式也可以用來將數據進行分類,下舉一例說明。
假設我們測試了1000個水果的數據,包括如下三種特徵:形狀(長?)、味道(甜?)、顏色(黃?),這些水果有三種:蘋果、香蕉、或梨子,如圖2所示。現在,使用一個貝葉斯分類器,它將如何判定一個新給的水果的類別?比如說,這個水果三種特徵全具備:長、甜、黃。那麼,貝葉斯分類器應該可以根據已知的訓練數據給出這個新數據水果是每種水果的概率。
首先看看,從1000個水果的數據中,我們能得到些什麼?
1.這些水果中,50%是香蕉,30%是蘋果,20%是梨子。也就是說,P(香蕉)=0.5,P(蘋果)=0.3,P(梨子)=0.2。
2.500個香蕉中,400個(80%)是長的,350個(70%)是甜的,450個(90%)是黃的。也就是說,P(長|香蕉)=0.8,P(甜|香蕉)=0.7,P(黃|香蕉)=0.9。
3.300個蘋果中,0個(0%)是長的,150個(50%)是甜的,300個(100%)是黃的。也就是說,P(長|蘋果)=0,P(甜|蘋果)=0.5,P(黃|蘋果)=1。
4.200個梨子中,100個(50%)是長的,150個(75%)是甜的,50個(25%)是黃的。也就是說,P(長|梨子)=0.5,P(甜|梨子)=0.75,P(黃|梨子)=0.25。
以上的敘述中,P(A|B)表示「條件B成立時A發生的概率」,比如說,P(甜|梨子)表示梨子甜的概率,P(梨子|甜)表示甜水果中,梨子出現的概率。
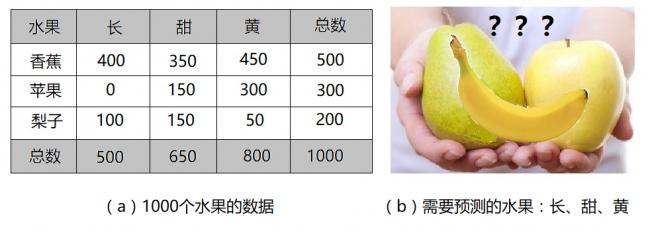
圖2:貝葉斯分類器
所謂「樸素貝葉斯分類器」,其中「樸素」一詞的意思是說,數據中表達的信息是互相獨立的,在該例子的具體情況下,就是說,水果的「長、甜、黃」這三項特徵互相獨立,因為它們分別描述水果的形狀、味道和顏色,互不相關。「貝葉斯」一詞便表明此類分類器利用貝葉斯公式來計算後驗概率,即:P(A|新數據)= P(新數據|A) P(A)/ P(新數據)。
這兒的「新數據」=「長甜黃」。下面分別計算在「長甜黃」條件下,這個水果是香蕉、蘋果、梨子的概率。對香蕉而言:
P(香蕉|長甜黃)= P(長甜黃|香蕉) P(香蕉)/ P(長甜黃)
等式右邊第一項:P(長甜黃|香蕉)= P(長|香蕉)* P(甜|香蕉)* P(黃|香蕉)=0.8*0.7*0.9=0.504。
以上計算中,將P(長甜黃|香蕉)寫成3個概率的乘積,便是因為特徵互相獨立的原因。
最後求得:P(香蕉|長甜黃)=0.504*0.5/ P(長甜黃)=0.252/ P(長甜黃)。
類似的方法用於計算蘋果的概率:P(長甜黃|蘋果)= P(長|蘋果)*P(甜|蘋果)* P(黃|蘋果)=0*0.5*1=0。P(蘋果|長甜黃)=0。
對梨子:P(長甜黃|梨子)= P(長|梨子)*P(甜|梨子)* P(黃|梨子)=0.5*0.75*0.25=0.09375。P(梨子|長甜黃)=0.01873/ P(長甜黃)。
分母:P(長甜黃)= P(長甜黃|香蕉) P(香蕉)+ P(長甜黃|蘋果) P(蘋果)+ P(長甜黃|梨子) P(梨子)=0.27073
最後可得:P(香蕉|長甜黃)=93%
P(蘋果|長甜黃)=0
P(梨子|長甜黃)=7%
因此,當你給我一個又長、又甜、又黃的水果,此例中曾經被1000個水果訓練過的貝葉斯分類器得出的結論是:這個新水果不可能是蘋果(概率0%),有很小的概率(7%)是梨子,最大的可能性(93%)是香蕉。
深度學習的奧秘
再看看,孩子們是如何學會識別狗和貓的?是因為媽媽帶他見識了各種狗和貓,多次的經驗使他認識了狗和貓的多項特徵,他便形成了自己的判斷方法,將它們分成「貓」、「狗」兩大類。科學家們也用類似的方法教機器學習。比如說,也許可以從耳朵來區別貓狗:「狗的耳朵長,貓的耳朵短」,還有「貓耳朵朝上,狗耳朵朝下」。根據這兩個某些「貓狗」的特徵,將得到的數據畫在一個平面圖中,如圖3b所示。這時候,有可能可以用圖3b中的一條直線AB,很容易地將貓狗通過這兩個特徵分別開來。當然,這只是一個簡單解釋「特徵」的例子,並不一定真能區分貓和狗。
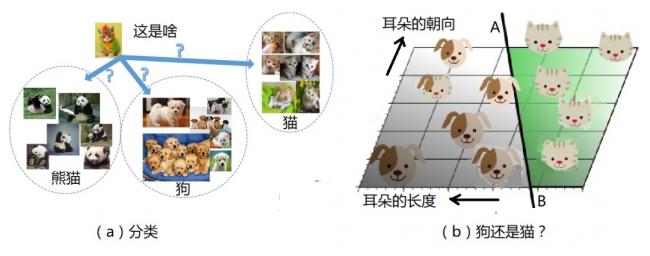
圖3:機器分類
總而言之,機器可以根據某個「特徵」,將區域作一個線性劃分。那麼,這條線應該畫在哪兒呢?這就是「訓練」過程需要解決的問題。在機器模型中,有一些被稱為「權重」的參數w1、w2、w3,……,「訓練」的過程就是調整這些參數,使得這條直線AB畫在正確的位置,指向正確的方向。上述「貓狗」的例子中,輸出可能是0,或者1,分別代表貓和狗。換言之,所謂「訓練」,就是媽媽在教孩子認識貓和狗,對AI模型而言,就是輸入大量「貓狗」的照片,這些照片都標記了正確的結果,AI模型調節權重參數使輸出符合已知答案。
經過訓練後的AI模型,便可以用來識別沒有標記答案的貓狗照片了。例如,對以上所述的例子:如果數據落在直線AB左邊,輸出「狗」,右邊則輸出「貓」。
圖3b表達的是很簡單的情形,大多數情況下並不能用一條直線將兩種類型截然分開,比如圖4a、圖4b、圖4c中所示的越來越複雜的情形,我們就不多談了。
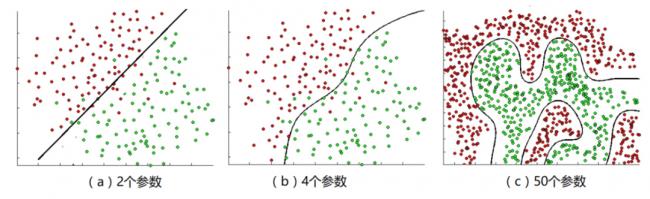
圖4:更多的特徵需要更多的參數來識別
判別式和生成式
在機器學習中的監督學習模型,可以分為兩種:判別式模型和生成式模型。從前面的敘述我們明白了機器如何「分類」。從這兩種學習方式的名字,可以簡單地理解為:判別式模型更多是考慮分類的問題,而生成式模型是要產生一個符合要求的樣本。
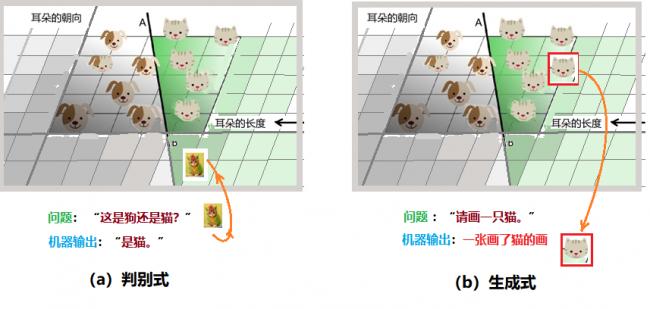
圖5:判別式和生成式的區別
還用識別「貓狗」的例子,用媽媽教孩子來打比。媽媽給孩子看了很多很多貓和狗樣本之後,指着一隻貓問孩子,這是啥?孩子回憶後作出判斷「是貓」,這就是判別式。孩子答對了很高興,自己拿起筆,在紙上畫出一個腦海中貓的形象,這就是生成式了。機器的工作也類似,如圖5所示,判別式中,機器尋找判別需要的分界線,以區分不同類型的數據實例;生成式模型則可以區分狗和貓,最後畫出一隻「新的」動物照片:狗或貓。
用概率的語言:設變量Y代表類別,X代表可觀察特徵。判別模型是讓機器學習條件概率分佈P(Y|X),即在給定的特徵X下類別為Y的概率;生成模型中機器對每一個「類別」都建立聯合概率P(X,Y)的模型,因而可以生成看起來像某種類型的「新」樣本。
例如,類別Y是「貓、狗」(0,1),特徵X是耳朵的「上、下」(1,2),假設我們只有如圖所示4張照片:(x,y)={(1,1),(1,0),(2,0),(2,0)}
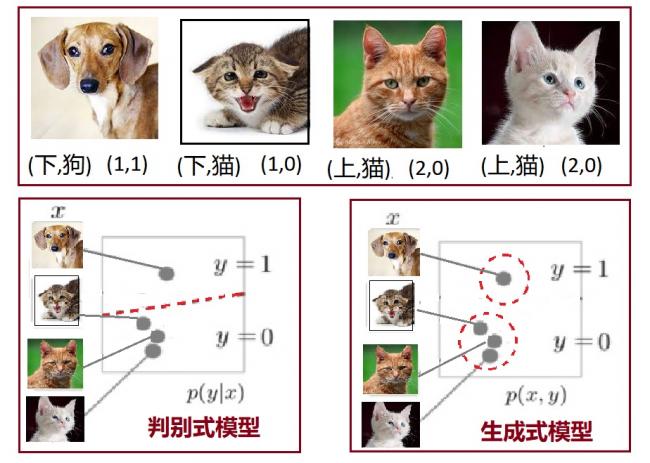
圖6:判別式和生成式建模的區別
判別式由條件概率P(Y|X)建模,得到分界線(左下圖中的紅色虛線);生成式由聯合概率P(X,Y)為每種類別建模,沒有分界線,但劃分了每個類型在數據空間的位置區間(右下圖中的紅色圓圈)。兩種方法根據不同的模型給出的概率來工作。判別式更簡單,只在乎分界線;而生成式模型要對每個類別都進行建模,然後再通過貝葉斯公式計算樣本屬於各類別的後驗概率。生成式信息豐富靈活性強,但學習和計算過程複雜,計算量大,如果只做分類,就浪費了計算量。
幾年前,判別式模型更受人喜愛,因為它用更直接的方式去解決問題,早就得到了不少的應用,比如垃圾郵件和正常郵件的分類問題等。2016年的alphago也是判別式應用作決策的典型例子。
ChatGPT的特點
如果你跟ChatGPT聊過天,一定會驚奇於它的涉獵極廣:創作詩歌、生成代碼、繪畫作圖、撰寫論文,似乎樣樣在行,無所不能。是什麼賦予了它如此強大的功力呢?
從ChatGPT的名字,我們知道它是一個「生成型預訓練變換模型」(GPT)。這裏包括了三個意思:「生成型「、」預訓練「、」變換模型」。第一個詞,點明它用的正是上面所介紹的生成型建模方法。預訓練,說的是它經過了多次訓練。變換模型是從「transformer」的英文翻譯過來的。變換器transformer於2017年由谷歌大腦的一個團隊推出,可應用於翻譯、文本摘要等任務,現被認為是處理自然語言等順序輸入數據問題NLP的首選模型。
如果你問ChatGPT自己,「它是什麼?」之類的問題,一般來說,它都會告訴你,它是一個大型的AI語言模型,這模型指的就是transformer。
這一類的語言模型,通俗的意思就是一個會「文字接龍」的機器:輸入一段文字,變換器輸出一個「詞」,對輸入文字進行一個「合理的延續」。(註:這兒我說輸出是一個「詞」,實際上是一個「token」,對不同的語言可能有不同的含義,中文可以是「字」,英文可能是「詞根」。)
其實,語言本來就是「接龍」。我們不妨思考一下孩子學習語言和寫作的過程。他們也是在聽大人說了好多遍各種句子之後學會怎麼說一句話的。學寫作也類似,有人說:「熟讀唐詩三百首,不會作詩也會吟」,學生看了大量別人的文章後,開始學寫作時,總會有所模仿,實質上就是無意識地學會了「文字接龍」。
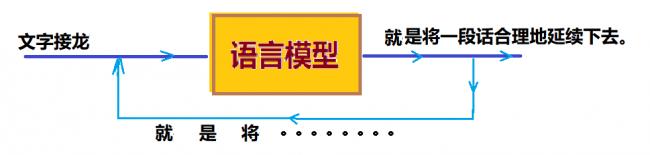
圖7:語言模型
所以實際上,語言模型所做的事情聽起來似乎極為簡單,基本上只是在反覆地詢問「輸入文本的下一個詞應該是什麼?」,如圖7所示,模型選擇輸出了一個詞之後,把這個詞加到原來的文本中,又作為輸入進入語言模型,又問同樣的問題「下一個詞是什麼?」。然後,再輸出、加進文本、輸入、選擇……如此反覆循環,直到生成一個「合理的」文本為止。
機器模型生成文本的「合理」或不合理,最重要的因素固然是所用「生成型模型」的優劣,再就是「預訓練」的功夫。在語言模型內部,對應一個輸入文本,它會產生一個可能出現在後面的詞的排序列表,以及與每個詞對應的概率。例如,輸入是「春風」,下一個可能的「字」很多很多,暫且只列舉5個吧,可以是「吹0.11、暖0.13、又0.05、到0.1、舞0.08」等等,每個字後面的數字表示它出現的概率。換言之,模型給出了一個帶有概率的(很長的)單詞列表。那麼,應該選擇哪一個呢?
如果每次都選擇概率最高的那一個,應該是不太「合理」的。再來想想學生學習寫作的過程吧,雖然也是在「接龍」,但是不同的人、不同的時候,有不同的接法。這樣才能寫出各種不同風格、又有創意的文章來。所以,也應該給機器隨機選擇不同概率的機會,才能避免單調平淡,產生出多姿多彩趣味盎然的作品。儘管不建議每次選擇概率最高的,但最好選擇概率偏高的,做出一個「合理的模型」。
ChatGPT是大型語言模型,這個「大」首先表現在模型神經網絡權重參數的數量上。它的參數數目是決定其性能的關鍵因素。這些參數是在訓練前需要預先設置的,它們可以控制生成語言的語法、語義和風格,以及語言理解的行為。它還可以控制訓練過程的行為,以及生成語言的質量。
OpenAI的 GPT-3模型具有1750億參數量,ChatGPT算是 GPT-3.5,參數數量應該多於1750億。這些參數指的是在訓練模型前需要預先設置的參數。在實際應用中,通常還需要通過實驗來確定適當的參數數量,以獲得最優的性能。
這些參數在成千上萬的訓練過程中被修正,得出一個好的神經網絡模型。據說GPT-3訓練一次的費用是460萬美元,總訓練成本達1200萬美元。
如上所述,ChatGPT的專長是生成「與人類作品類似」的文本。但一個能夠生成符合語法的語言的東西,未必能夠進行數學計算、邏輯推理等等另一些類型的工作,因為這些領域的表達方式完全不同於自然語言文本,這也就是為什麼它在數理方面的測試中屢屢失敗的原因。
此外,人們也經常發現ChatGPT「一本正經地胡說八道」的笑話。其原因不難理解,主要還是訓練的偏向問題。某些它完全沒有聽過的東西,當然無法給出正確的回答。還有多義詞帶來的問題,也給機器模型困惑。例如,據說有人問ChatGPT「勾三股四弦五是什麼」的時候,它一本正經地回答說:「這是中國古代叫做『琴』的一種樂器的調弦方法,然後還編造了一大堆話,令人捧腹不已。
總之,ChatGPT一上場就基本取得成功,旗開得勝,這也是概率論的勝利,貝葉斯的勝利。
——————
參考文獻
1.張天蓉.趣談概率-從擲骰子到阿爾法狗[M].北京:清華大學出版社,pp.71-75,2017年
2.Sean R Eddy,「What is Bayesian statistics?」,[J], Nature Biotechnology22,1177-1178(2004).
3.Jake VanderPlas,「Frequentism and Bayesianism: A Python-driven Primer」,[L], arXiv:1411.5018[astro-ph.IM],2014. https://arxiv.org/abs/1411.5018
4.Russell, Stuart; Norvig, Peter(2003)[1995]. Artificial Intelligence: A Modern Approach(2nd ed.).[M], Prentice Hall. p.90



















{kind=link}