中國社交平台微信近期推出「方言採集」返現活動,邀請用戶錄製各地方言語音(即聲紋)以換取現金獎勵。活動上線後,有參與者稱累計獲得數百元收益。隨着參與範圍擴大,討論延伸至個人私隱問題,方言曾被網民視為相對隱蔽的交流方式,其安全性與可識別性開始引發關注。
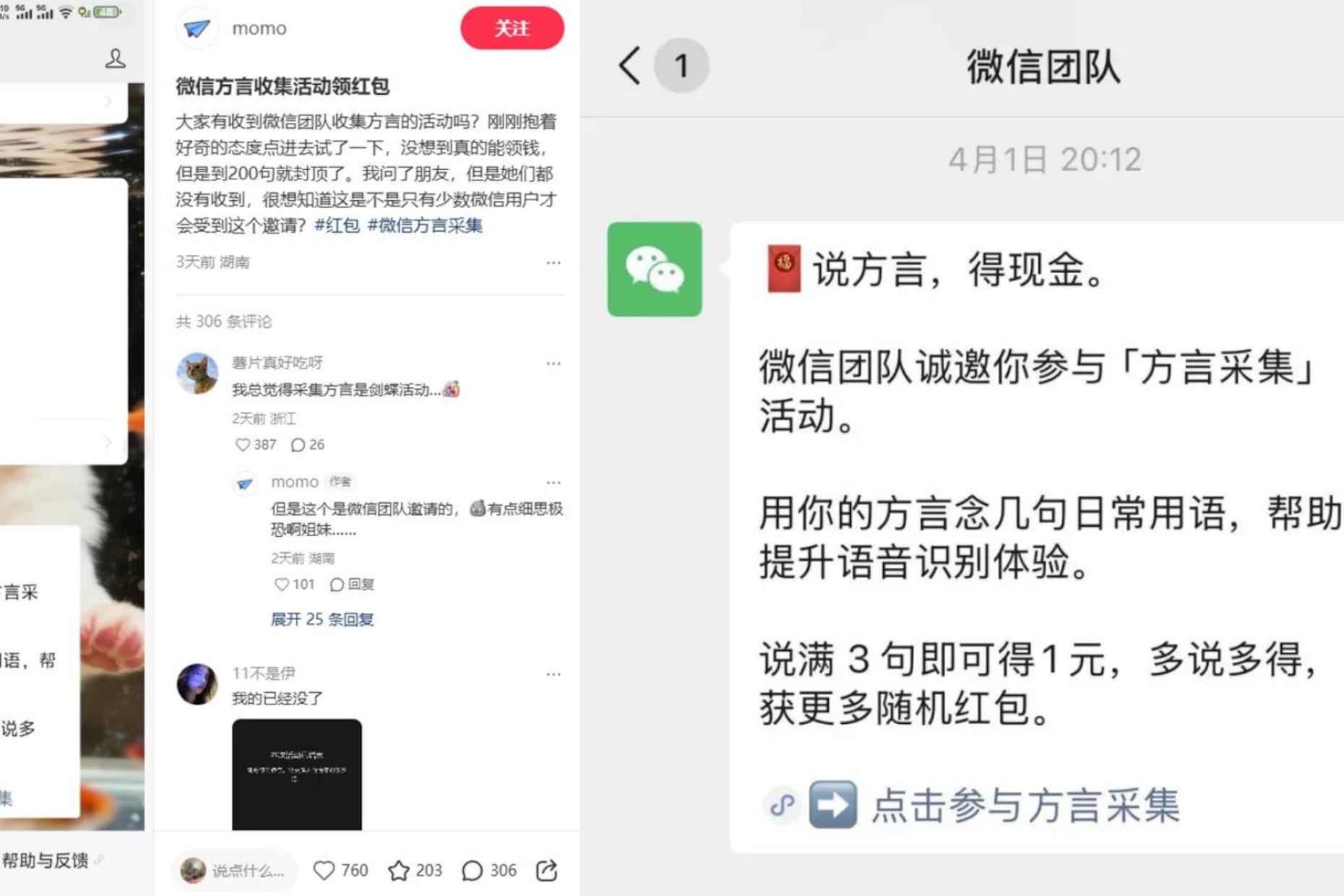
據極目新聞4月10日報道,微信通過邀請方式向部分用戶推送「方言採集」任務。參與者按提示朗讀日常用語,完成語音錄入即可獲得現金獎勵。有用戶在社交平台展示收益截圖,稱單日收入約40元。
浙江從事語音識別研究的工程師黃一鳴接受採訪時說,中國方言有上百種,甚至更多,另外還有方言變種,常說「十里不同音,百里不同俗」,如果細分到縣、鄉、村,更無法統計:「方言語音數據一直比較缺,差異大,比如溫州話複雜,很多地方人都聽不懂,標註也比較難,通過對用戶錄音補充這些資料,是他們想做的事,可以提高模型在複雜語音環境下的識別能力,徵集這類數據主要收集做語音模型。」
有償徵集方言模型引熱議
用戶在微信平台錄入當局指定的文字語音,審核通過後獎勵將在30天內發放至微信零錢。據了解,用戶每錄滿3句可獲得約1元,錄滿20句可獲5元,實際錄製量多在每天100至200句之間。
據報道,中國130多種語言及各類方言中,68種使用人口不足萬人,48種不足五千人,25種已不足千人。
對於微信平台為何花錢徵集方言語音,黃一鳴表示,平台需要提升網民語音識別準確率:「至於它的用途,我想大家都清楚,如果在微信用語音聊天,它是有工具識別的,但是沒有該方言的模型,就解不開,或者說難度比較大。」
活動擴大後,討論開始從技術本身轉向這些語音數據可能的用途。長期以來,方言在一些非正式交流中被視為相對隱蔽的表達方式,識別難度在一定程度上降低了被自動化處理的可能。微信方面表示,該項目用於「提升語音識別體驗」。
網民憂方言識別被「濫用」
「連家鄉話都不安全了。」一條在社交平台獲得較多回應的留言這樣寫道。該評論下方,多名用戶提到,過去使用方言交流的一個原因,是降低被系統識別的可能性。
山東滕州網民齊先生告訴記者,當地有很多種方言:「滕州一個小小的地方,東西南北說話都不一樣,如果你語音輸入,它微信加不上無法識別,我覺得他們現在就是在收聲音數據,他在語音識別監控方面,肯定有很大的幫助。」
關注個人私隱議題的學者余文天認為,這項技術本身不是問題,關鍵在於它會被用來做什麼。他對記者說:「如果是把方言轉成文字,這是有意義的,也應該肯定,但如果是用於審核方言內容,對批評言論進行干預,那對大部分網民來說,不是好事。」
近年來中國在金融、電信等領域逐步引入聲紋識別技術,用於身份驗證與風險控制。所謂聲紋,是一種生物特徵,簡單來說就是人聲的「指紋」,能夠用於標識說話人身份。中國一些平台也已具備語音轉寫與內容審核能力。從事語音技術研究的人士指出,隨着人工智能模型訓練推進,語音數據在各類應用中的作用正在增加。
截至目前,微信方面未就數據管理細節作出進一步說明。該活動仍處於邀請階段,尚未全面開放。
(微信截圖)



















{kind=link}