你見過這樣的「盲眼」機械人demo嗎?
它在完全看不見的情況下——沒有攝像頭、雷達或任何感知單元——主動搬起9斤重的椅子,爬上1米高的桌子,然後翻跟頭跳下。

不光耍酷,干起活來,搬箱子也不在話下。

還能一個猛子跳上桌子。

手腳並用爬坡也照樣OK。

這些絲滑小連招來自亞馬遜機械人團隊FAR(Frontier AI for Robotics)發佈的首個人形機械人(足式)研究成果——OmniRetarget!
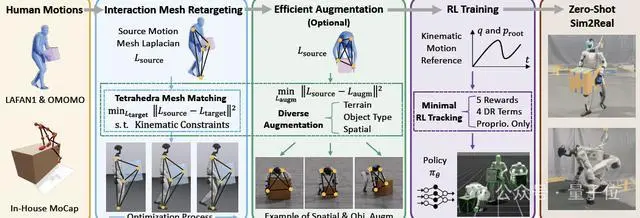
OmniRetarget使強化學習策略能夠在複雜環境中學習長時程的「移-操一體」(loco-manipulation)技能,並實現從仿真到人形機械人的零樣本遷移。

網友表示:又能跑酷、還能幹活,這不比特斯拉的擎天柱強10倍?

接下來,讓我們一起看看他們是怎麼做到的吧!
基於交互網格的動作重定向方法
總的來說,OmniRetarget是一個開源的數據生成引擎,它將人類演示轉化為多樣化、高質量的運動學參考,用於人形機械人的全身控制。

與通常忽略人-物體/環境之間豐富的交互關係的動作重定向方法不同,OmniRetarget通過一個交互網格(interaction mesh)來建模機械人、物體和地形之間的空間和接觸關係,從而保留了必要的交互並生成運動學可行的變體。
此外,保留任務相關的交互使得數據能夠進行高效的數據增強,進而從單個演示推廣到不同的機械人本體、地形和物體配置,以減少不同變體的數據收集成本。
在與其他動作重定向方法的對比中,OmniRetarget在所有關鍵方面:硬約束、物體交互、地形交互、數據增強表現出了全面的方法優勢。

接下來就讓我們具體來看。
首先,OmniRetarget通過基於交互網格(interaction-mesh)的約束優化,將人類示範動作映射到機械人上。
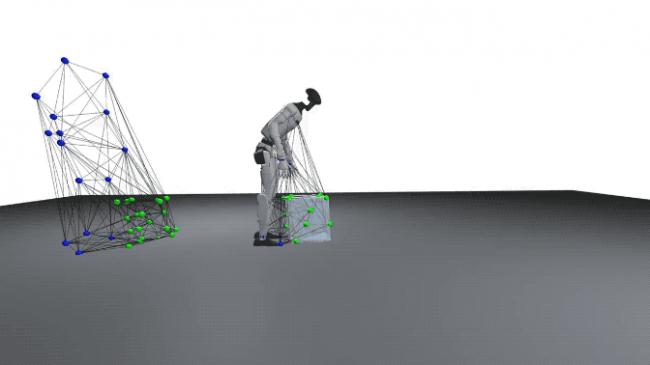
在研究中,交互網格被定義為一個體積結構,用於保持身體部位、物體與環境之間的空間關係。
交互網格的頂點由關鍵的機械人或人類關節以及從物體和環境中採樣的點組成。
通過收縮或拉伸該網格,研究可以在保持相對空間結構和接觸關係的前提下,將人類動作映射到機械人上。
在交互網格的構建過程中,研究人員對用戶定義的關鍵關節位置以及隨機採樣的物體和環境點應用德勞內四面體化(Delaunay tetrahedralization)。
(註:為了更精確地保持接觸關係,物體和環境表面的採樣密度高於身體關節的採樣密度。)
研究通過最小化源動作(人類示範關鍵點及對象/環境採樣點)與目標動作(機械人對應關鍵點及相同對象/環境點)之間的拉普拉斯形變能(Laplacian deformation energy),讓機械人動作儘量保持與人類示範一致的空間和接觸關係。
拉普拉斯坐標衡量每個關鍵點與其鄰居點之間的相對關係,從而在重定向動作時保留局部空間結構和接觸關係。
在每個時間幀,算法通過求解約束非凸優化問題來獲得機械人配置,包括浮動底座的姿態和平移以及所有關節角度,同時滿足碰撞避免、關節和速度限制,以及防止支撐腳滑動等硬約束。
優化則使用順序二次規劃風格的疊代方法,每幀以上一幀的最優解作為初值,以保證時間上的連續性和平滑性。
由此,基於交互網格的方法可適配不同機械人形態和多種交互類型,只需調整交互網格中的關鍵點對應關係和碰撞模型。

其次,每一次空間和形狀的增強都被視為一個新的優化問題,從而生成多樣化的軌跡。

具體來說,OmniRetarget通過參數化地改變物體配置、形狀或地形特徵,將單個人類演示轉化為豐富多樣的數據集。
對於每個新場景,研究都會使用固定的源動作集和增強後的目標動作集重新求解優化問題:通過最小化交互網格的形變,可以得到一組新的、運動學上有效的機械人動作,同時保留原始交互中的基本空間結構和接觸關係。
在機械人-物體的交互中,研究通過增強物體的空間位置和形狀來生成多樣化的交互(位姿和平移進行增強,並在局部坐標系中構建交互網格)。
為避免整個機械人隨物體發生簡單剛體變換,研究還在優化中加入約束,將下半身固定到標稱軌跡,同時允許上半身探索新的協調方式,從而生成真正多樣化的交互動作。
在機械人-地形的交互中,研究通過改變平台的高度和深度,並引入額外約束來生成多樣化的地形場景。
最後,在建立了高質量運動學參考的方法之後,研究使用強化學習來彌補動力學差異,即訓練一個低層策略,將這些軌跡轉化為物理可實現的動作,實現從仿真到硬件的零次遷移。
得益於乾淨且保留交互的參考數據,OmniRetarget僅需最小化獎勵即可高保真跟蹤,無需繁瑣調參。
訓練時,機械人無法直接感知明確的場景和物體信息,僅依賴本體感知和參考軌跡作為複雜任務的先驗知識:
參考動作:參考關節位置/速度,參考骨盆位置/方向誤差
本體感受:骨盆線速度/角速度,關節位置/速度
先前動作:上一時間步的策略動作
在獎勵方面,研究使用五類獎勵(身體跟蹤、物體跟蹤、動作速率、軟關節限制、自碰撞)來保證動作質量,同時結合物體參數和機械人狀態的領域隨機化提升泛化能力。
此外,相似動作會分組訓練以加快策略收斂,不同的任務(如搬箱和平台攀爬)則採用不同策略設置。

實驗結論
在實驗方面,研究團隊首先展示了OmniRetarget能實現的複雜行為的廣度,包括自然的物體操作和地形交互。
然後提供了針對最先進基線的定量基準測試,評估了在運動學質量指標和下游策略性能方面的表現。
正如我們開頭所展示的,搭載OmniRetarget的宇樹G1實現了一個類似波士頓動力的跑酷動作。
這個持續30秒、複雜的多階段任務突顯了OmniRetarget生成精確且通用參考動作的能力。
在可擴展性上,OmniRetarget在完整增強數據集上訓練和評估成功率為79.1%,與僅使用標稱動作的82.2%相近,說明運動學增強在不顯著降低性能的情況下實質性擴大了動作覆蓋範圍。
最後,研究團隊將OmniRetarget與PHC、GMR和VideoMimic等開源重定向基線進行了比較。
(註:實驗使用OMOMO、內部MoCap和LAFAN1數據集進行評估)
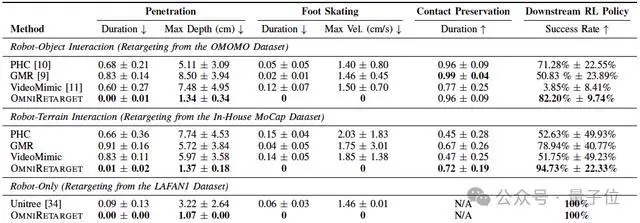
實驗結果顯示,在運動學質量上,OmniRetarget在穿透、腳部打滑和接觸保留指標上整體優於所有基線,即使偶爾輕微穿透也能被 RL修復。
下游強化學習策略評估表明,高質量重定向動作直接提升策略成功率,OmniRetarget在所有任務中均領先基線10%以上,且表現更穩定。
One more thing
值得一提的是,OmniRetarget背後的Amazon FAR(Frontier AI& Robotics)成立僅七個多月,由華人學者領銜。
FAR的前身是著名機械人技術公司Covariant,創始人均為出自UCBerkeley的Pieter Abbeel、Peter Chen、Rocky Duan和Tianhao Zhang。
(註:Pieter Abbeel是Rocky Duan和Tianhao Zhang的導師)
其中,Pieter Abbeel可謂是機械人領域的大佬,他是伯克利機械人學習實驗室(Berkeley Robot Learning Lab)主任以及伯克利人工智能研究實驗室(Berkeley AI Research, BAIR)的聯合主任。

早在去年8月,亞馬遜就與Covariant達成協議,獲得該公司技術的「非排他性」許可,聘用Covariant四分之一的員工,同時Covariant的創始人Pieter Abbeel、Peter Chen、和Rocky Duan也將加入亞馬遜。
目前,由Rocky Duan擔任Amazon FAR研究負責人。
而OmniRetarget這次令人驚艷的亮相,正是Amazon FAR在人形機械人(足式)領域的首次嘗試。
不得不說,亞馬遜(Amazon)的機械人,真的有點驚艷(Amazing)。
已經開始期待他們之後的工作了!

















{kind=link}