最近,AI作畫拿大獎的事挺火。
在今年8月的科羅拉多州博覽會的藝術創作比賽中,出現了這樣一組復古風格的科幻題材作品,穿着禮服的舞者們在宇宙背景下翩翩起舞,仿佛是栩栩如生的太空歌劇。
評委們立刻就被這組驚艷的作品圈粉了,就你沒跑了!直接把數字藝術賽道的大獎頒發給了它的創作者傑森·艾倫。

不過此等大佬為啥在業內從來沒聽過他的名字,難道是什麼世外高人?
結果沒幾天藝術家們就集體繃不住了——這位老哥在Discord論壇自曝了,自己是個遊戲公司的老闆,根本不是藝術家,參賽作品是他用一個叫做Midjourney的人工智能畫的。

有人認為,這種作品根本沒資格參加評選,因為傑森本人根本沒付出什麼努力。但傑森表示:比賽嘛,重要的是結果,你們又沒說不讓用AI。雖然爭議很大,但主辦方並沒有收回頒獎結果,因為他們確實沒禁止AI參賽……
但藝術家們的破防也是貨真價實的。
雖然我自己不是美術生,但也多少知道他們為了走上藝術道路,付出了多大的努力。
我國每年大約有60萬學子參加美術藝考,他們之中很多人高中甚至初中還沒畢業,就要獨自來到陌生的城市求學,幾年如一日地架着畫板,訓練技法,培養美感,直到考上心儀的院校,藝術之路才算真正開始。
每一張別出心裁的海報、「紙片人老婆」的精美立繪、美術展上讓人不明覺厲的畫作,這些背後往往都有着數十年的努力和積累。
但這些都被一個名不見經傳的AI,用一分鐘都不到的創作給打敗了,多少會讓人有些懷疑人生。
這感覺就好比你努力一生終於成為一名絕世劍客,渴望一場堂堂正正的比武,結果對面不講武德,掏出機關槍一頓輸出,你作何感想?

再嚴重一些,如果AI創作功力恐怖如斯,最終會搶走藝術家們的飯碗嗎?
01AI作畫真的有那麼簡單嗎
想要知道AI到底會如何影響創作者,最簡單的辦法就是親自去試試,比如幫傑森·艾倫拿獎的那個Midjourney。
它的玩法非常簡單,在聊天的對話框裏敲入特定的命令行,然後再銜接上自己對圖像的文字描述,回車後ai就會生成4張符合描述的草圖。
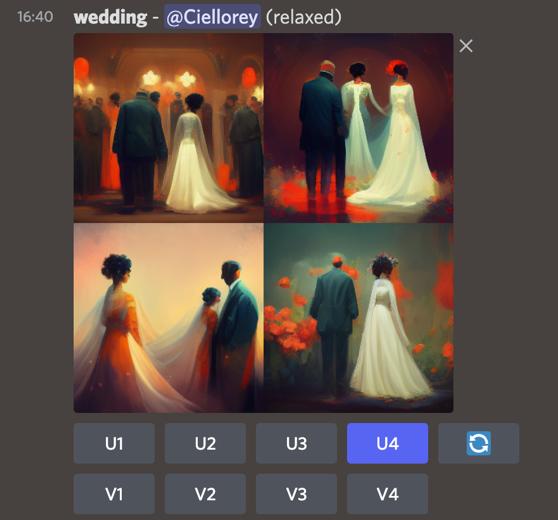
下面有兩行按鈕,「U」是upscale的縮寫,功能是把對應序號的圖片添加更多細節,輸出一張尺寸更大的成品圖。
「V」是variety的縮寫,功能是按照對應序號的圖片再生成四張風格、構圖差不多的草圖。
細化後的完成圖除了輸出幾種不同精細度和解像度的衍生圖外,還有個「重製(Remaster)」功能,雖然沒太搞懂它重製的邏輯是什麼,有時候連畫風都給你改了,但有時候也能化腐朽為神奇。

Remaster後反而更有二次元的感覺了
想要得到一張滿意的圖像,怎麼給AI提需求是非常講究的,比如除了講清楚要畫的東西,還可以指明想要的美術風格、細節豐富度、打光方式什麼的。另外就是要多次嘗試了,會有碰運氣的成分在。
作為一個《原神》玩家,我第一反應就是讓AI給我畫一個帥氣的鐘離,輸入的關鍵詞包括Zhongli, Morax, Genshin Impact這些,可在經過反覆幾次疊代後,我得到了個什麼鬼!
你要說毫無關係吧,這衣服的色系還有那麼一點感覺,你要說有關係吧,這岩王帝君被磨損得渣都不剩了嗎?

Zhongli, Morax, Genshin Impact
不過在出圖的過程中,我也得到了一些雖然毫無關係、但驚艷至極的圖片,比如這兩幅。

Zhongli, Genshin Impact
嗯……勉強解釋為帝君在渡劫?還有這種霸氣的肖像,是平行世界的鐘離嗎?不過也挺帥的:

Morax, Genshin Impact
鍾離老爺子在國外也挺火的啊,為啥AI就不識別了呢?感覺我的關鍵詞鎖得差不多啊……
迫害完了鍾離,再來迫害一下雷電將軍(Raiden Shogun)。於是,得到了下面這些圖片。

Beelzebul, Raiden Shogun, female, Genshin Impact
帥是真的帥,但我想要的是煮飯婆啊!然後我又用派蒙、神里綾華、八重神子、小吉祥草王試了下,不能說是一模一樣,只能說是毫無關係。
現在終於可以確認,雖然原神可以說是市面上最火的遊戲,但以目前這個AI的學習程度和「閱片量」,它還理解不了「原神」是什麼。
如果是那種在中西方語境下完全家喻戶曉的高人氣角色,AI能精準狙擊嗎?比如,咱們的齊天大聖孫悟空……
一通嘗試後,效果還是挺不錯的!

Sun Wukong,Cyberpunk style

Sun Wukong, Sumurai

Ninja Sun Wukong

Sun Wukong wearing a glasses

Sun Wukong made of fire
但創作過程中也有很多問題。最頭疼的是AI總是試圖把Sun(孫)理解成sun(太陽),經常會出現帶有太陽的風景畫。

Sun Wukong, shoot in the universe,4k, hyperrealistic, unreal engine
看來即便是AI,理解中文也是頗有難度的。如果換成國外家喻戶曉的IP,比如比卡丘,創作過程就會容易很多,甚至可以繪製出一整套賽博比卡丘軍團。
而且通過調整關鍵詞,還能改變作畫的風格,比如下面這張賽博比卡丘(Cyber Pikachu)就偏2D風格。

Cyber Pikachu
如果再加上「4k, intricate details(複雜細節), cinematic(電影效果), hyperrealistic(超現實), raytracing reflections(光線追蹤反射),3d matte painting(3D無光繪畫)」這麼一長串的限定詞,就能夠做出光影效果特別棒的3D渲染效果圖。

pikachu, cyberpunk style,4k, intricate details, cinematic, hyperrealistic, raytracing reflections,3d matte painting
乍一看這些圖渲染精度都挺高的,但也會存在明顯的細節錯誤。
比如不管我怎麼畫,都沒看到比卡丘那個標誌性的閃電尾巴,也經常會出現一些低級的作畫錯誤,比如畫人類的手對AI就是老大難問題。看得出,摳細節目前還並不是Midjourney的強項。
再比如最近很多人嘗試讓AI畫二次元萌妹,拿出了一堆關鍵詞,我也用大佬的關鍵詞試了一下,想要得到好看的妹紙還要多次疊代,挺看運氣的。

逐步疊代成形的多細節二次元萌妹
那它更擅長什麼呢?
經過兩周多的深度體驗,我發現Midjourney對於不用太摳細節的大場景繪製非常出色。比如群里的小夥伴說自己夢到「充滿科技感的盤根錯節的大樹」,經過一段時間的嘗試,我就得到了一些相當符合她要求的作品。

white mechanical banyan, science fiction style
當然,開始也整出了一些相當掉san的玩意兒……而且我發現,這個AI對於克系元素把握相當出色,還真的是萬物皆可「克蘇魯」。

a tree made of many white mechanical octopus foot
還有就是對於一些日常用品和貓貓狗狗什麼的,Midjourney的正確率也相當高。而且如果還可以把這些東西融合起來,做出很多有趣的設計,比如下面這組「元素貓(cat made of XXX)」:

cat made of XXX
其實,只要玩得夠久,AI總能陰差陽錯地畫出幾張非常漂亮的圖,哪怕它已經和最開始的需求相差萬里了……
但這個過程就跟刷短視頻上癮一樣,總是能給我帶來一波又一波的驚喜:

03AI作畫是如何煉成的
經過成百上千張圖的嘗試,我們可以總結一下目前以Midjourney為代表的AI作畫特點:風格、創意、構圖、顏色搭配上,對於我這個外行人可以說是無可挑剔,但作畫細節還很經不起推敲。
這個就特別AI,總會在你意想不到的地方驚艷,也會在你覺得理所應當的地方差強人意。
可即便如此,AI作畫也已經足夠驚艷了,兩年前的我們恐怕根本想不到AI能進化到這種程度。很早之前,AI就能很好地將圖片分類,甚至在圍棋和《星際2》上爆打人類,今天的AI和當時相比又有哪些進步呢?
在去年,OpenAI通過4億張網絡圖片,訓練出一個叫做CLIP的AI模型。和之前那些做圖像分類的模型不同,CLIP的作用是把圖像和文本做關聯,訓練的目的也不是為了分類,而是判斷文本和圖像是否匹配。
因為網絡上的圖片普遍是帶有描述它們的標籤的,而且圖像的類別更豐富,內容也更複雜。以往的訓練集標籤可能只是「貓」、「狗」、「卡車」這樣單一的標籤,但網絡圖片可能是「一隻狗在車上玩球」這樣複雜的描述。
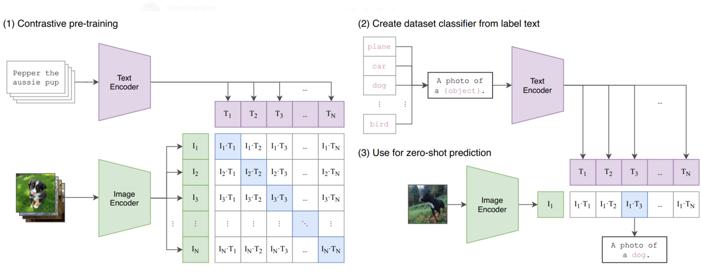
CLIP模型
訓練後,CLIP模型的任務就是根據輸入的文本描述,提煉出這段描述中包含的圖像特徵。比如說,「紅色的深淺」就可以是一個維度,「圓潤程度」是另一個維度,「光澤程度」也是一個維度……
根據這三個維度,就可以在一個三維空間內定義特定的物體,比如一個「紅色金屬圓球」。
但這幾個維度顯然是不夠的,CLIP最終能夠提取幾百個「特徵」,形成一個人類根本無法理解的超維度空間。這裏有趣的地方就來了,AI對於特徵的理解,可能和人類完全不一樣。
比如人類理解的是「高矮胖瘦、紅橙黃綠」這些比較視覺化的特徵,但AI眼中的特徵……很多可能人類根本無法理解。但由於訓練數據足夠龐大且複雜,AI就可以通過這幾百個特徵,找到輸入的描述在超空間的位置。
幾百個特徵就可以包羅萬象了麼?還是那個問題,也許對於人類不可能,但對於理解更抽象特徵的AI就不一樣了,雖說現在的AI想理解所有的概念還不現實,但對於生活中常見事物的理解其實已經非常到位了,甚至能融合兩種根本不沾邊的事物。
CLIP模型之所以效果這麼好,關鍵是用了4億張網絡圖片來訓練,這個工作量可以說是非常恐怖了,也只有OpenAI這種行業一哥能把持得住。這個模型其實早年間就提出過,但因為數據量不夠,效果並不理想。現在這一波可以說是力大磚飛了。
理解了輸入文本的含義,得到了抽象的特徵後,接下來就要生成圖像了。在圖像生成算法上,AI也經歷了一次重大的升級。之前普遍用到的是「對抗生成網絡(GAN)」模型。

對抗生成網絡
簡單來說就是一個AI專門負責畫畫,另一個AI專門負責判斷它畫的好不好。
這兩個AI一開始可能都很菜,但在二者不斷「相愛相殺」後,就會像鳴人和佐助一樣共同進步,從而讓生成的圖像越來越符合要求,各種基於對抗生成網絡的模型也此起彼伏,比如英偉達用來生成真實人臉的StyleGAN。

StyleGAN
但也就在今年,對抗生成網絡被一個叫做擴散模型的算法給打敗了,逐漸成為了現在主流的圖像生成算法。

擴散模型
讓AI作畫名聲大噪的Dall-E2就是通過「CLIP模型+擴散模型」,來實現「文本生成圖像」的飛躍式進步的。雖然OpenAI官方並沒有開源Dall-E2,但他們卻把CLIP模型開源了,這才讓一大波民間的AI作畫應用普及開來。
像是現在效果比較好的Midjourney和Stable Diffusion,它們的興起也就是兩三個月的事兒。

Dall-E2的成名作
更讓人意想不到的是,似乎AI界現在已經不滿足於單純生成圖像了,視頻也開始安排上了,絕望的看來不僅是設計師和藝術家了,難道視頻剪輯和後期的崗位也岌岌可危了嗎?
04版權與偏見
雖然AI作畫初出茅廬就大殺四方,但其實它本身也是存在問題的。
比如讓人很頭疼的版權問題。
就拿Midjourney為例,理論上付費用戶生成的圖片不存在版權問題,但在實際使用中還是會產生諸多問題。比如我用它畫了個米老鼠,然後商用了,那迪士尼會不會找我麻煩?
理論上AI作畫的原則是要避免出現現實中特定的人,畢竟不管是出於政治還是私隱問題都挺麻煩的。
但也不知道是由於疏漏還是單純樂子人心態,「Trump」一直都沒有被列入Midjourney的屏蔽敏感詞。輸入「川普+克蘇魯」,大部分出圖還真就挺地道的,川普的髮型,沒個幾百張圖片估計是學不來的。

還有一些人通過AI作畫看到了商機,把自己通過AI生成的圖片大量地掛到各種付費資源網站來售賣。他們是爽了,但這對平台方可能就不爽了。
這同樣涉及到AI訓練集的圖片來源問題。比如CLIP的4億張網絡圖片,保不齊就存在一些侵犯肖像權的問題。
比如有人就在LAION數據集中發現了自己早年間去醫院看病的照片,這個數據集就曾經被Stable Diffusion使用過。當時拍攝是出於治療目的,但她不知道為啥這些照片就流傳到網絡上了。
那通過這些存在侵權問題的樣本生成的圖像,是不是也存在這些侵權問題呢?至少現在哪個國家的法律都是模稜兩可的,畢竟嚴格來說,畫畫的是AI不是人,貌似還沒有給AI定罪的法律吧!
最後,訓練用的網絡圖片可能本身存在由於文化和語言帶來的偏見。比如在Midjourney上用CEO作關鍵詞,大概率生成的是歐美人形象。
從原理上來說這很正常,畢竟訓練的樣本可能大部分來源於谷歌,但從結果上來說,這是否也讓AI帶有某種與生俱來的偏見呢?

再比如訓練模型對於中文的支持非常差,但如果全部翻譯成英文,就會出現很多奇怪的bug,就比如前面提到的:Midjourney至今還不認識岩王帝君,想要個齊天大聖卻總是畫一個太陽。
最好的辦法當然是我們要有屬於自己的中文AI大模型,各個大廠其實已經低調搞了很久了。拿我最愛的雙馬尾、白髮紅瞳老婆測試了一下,雖然可拓展延伸的選項沒那麼多,但出圖可以說是深得我心啊!
最關鍵的是,直接輸入中文就行了啊!很多國人的XP你告訴我要怎麼翻譯成英文啊!

雖然想要讓它生成個「鍾離」也不太現實,但最起碼這個人物畫風、穿搭、背景風格,確實有那個意思了,第四張是琴團長和爺的合體嗎?用國產AI來做原神二創,是真的未來可期。

尾聲
發現了麼?幾年前AI還只是一幫算法工程師們琢磨的高端玩意兒,不僅效率低,還特別的「人工智障」。如果什麼產品說用到了AI技術,大概率是在割韭菜。
但也就這幾年,AI的發展速度突飛猛進,雖然依舊缺乏常識,但它不僅不再智障,還一躍成為各行各業的潛力股。到現如今的AI作畫,甚至已然成為每個普通人都能觸及的工具。
那回到最開始的問題,AI作畫會搶走人類的飯碗嗎?這個問題得從短期和長期來看。
從短期來說,AI作畫雖然整體的畫風和氛圍非常到位,但具體的細節表現不僅差強人意還毫無常識。比如有做獨立遊戲的群友想要畫個二次元弓箭手,雖然整體觀感出來了,但AI始終畫不好弓箭的結構。想要AI自己畫出完全符合要求的圖幾乎不可能,還是需要設計師或者藝術家來精雕細琢的。

而且AI並不是一個足夠聽話的「乙方」,人類設計師可以根據甲方的需求對圖像進行像素級的修改,哪怕是「五彩斑斕的黑」也能給你糊弄出來。
AI的腦迴路就離了大譜了,雖然不知疲倦任勞任怨,但它好像永遠都得貫徹點自己的想法,從而忽略部分具體的需求。往往你提的要求越具體,它就越是唱反調。
所以,現在的AI其實更適合做前期的創意支持工作。比如我是一個經驗豐富的設計師,接到一個甲方的需求,但我腦子裏暫時沒啥想法,那我就可以先跑幾張AI畫的圖找找靈感,畢竟「腦迴路」跟人類不太一樣,說不定能有一些讓我耳目一新的創意,然後自己再動筆就能起到事半功倍的效果。

對於一些沒學過畫畫、又急需美術資源的人,AI作畫的作用就更大了。
比如我是個獨立遊戲開發者,想做一個文字AVG遊戲,但我請找不到美術設計,直接用現成的資源還能有版權問題,用AI作畫不就行了嗎?
比如我就可以用Midjourney來畫它最擅長的場景圖,再用Crypko生成個二次元半身立繪,組合一下是不是有那味兒了?

所以我認為,無論你是不是美術從業者,短期內AI都不會讓人類丟掉飯碗,它還存在不小的短板,需要更多算法的疊代和樣本的投餵。
從長期看呢?如果AI通過幾個版本的疊代補齊了自身的短板,甚至還能自動把圖像分圖層、做成工程文件來讓人調整細節,哪些人會受到影響呢?
我認為,對於行業大佬和繪畫小白來說,AI可能依舊是很好的輔助工具,最尷尬的是那些處於中間段位的選手們。
一個初出茅廬的畫師,養家餬口都是問題,本來就少有時間精雕細琢自己的作品,現在還突然蹦出水平不錯的AI,最可氣的是你還未必畫得有它好,十幾年的磨練還不如餵幾個月的數據,是誰都會受挫的。而且從公司成本考慮,如果AI比絕大部分畫師畫得好,那老闆很難不心動啊,傳統的美術崗位可能真的會被AI取代。
但這也許不意味着很多人會失業。在這裏我大膽腦補一下,不久後會誕生一個新的職業,叫做「AI吟唱師」。
就像奇幻作品中的大魔法師利用超長的吟唱和複雜的符文構建高位魔法一樣,AI吟唱師通過熟練運用各種AI的特性,挑選一長串複雜的關鍵詞,讓AI生成符合需求的圖片甚至視頻。這個崗位仍然需要有經驗的畫師來完成,到那時,原生的創意和審美和審美可能會更偏重一些。

想要AI聽話,需要吟唱的關鍵詞還挺多的
這可不僅僅是美術行業的問題,未來的AI,肯定會涉足寫作、編程、視頻後期等領域。這個未來何時會到來呢?
還真不好說,畢竟AI的進步速度已經遠超人類的想像了,我們與其抵制浪潮的到來,不如先學會游泳。畢竟作為人類,作為AI的創造者,我們總能找到出路。
縱觀歷史,蒸汽機、攝影、火車、交流電、電視、電腦、手機、互聯網,新技術的誕生總會讓一些人感到恐懼。但事實證明,只要給予足夠的時間,哪怕會產生波瀾甚至動盪,人類總能和新技術的產物和諧共處,帶來一次又一次顛覆認知的變革。
我們能夠駕馭過去的技術,AI又有什麼理由不行呢?


















{kind=link}