自從1892年首次出現在一本德國雜誌上之後,這張圖就一直持續引發爭議。有些人只能看到一隻兔子,有些人只能看到一隻鴨子,有些人兩個都能看出來。
心理學家用這張圖證明了一件事,視覺感知不僅僅是人們看到了什麼,也是一種心理活動。但是,這張圖到底應該是什麼?
上周四,有位學者決定讓沒有心理活動的第三方看一下。然後就把這張圖片給了谷歌AI,結果AI認為78%的概率是一隻鳥,68%的概率是一隻鴨子。
所以,百年爭論可以歇了?鴨子派勝出?
不不不,新的爭論剛剛開始。
這下難倒了谷歌AI
上面那個結論剛出,就有人跳出來「抬槓」。
只要把這張圖豎起來給AI看,它認為是一隻兔子,壓根就沒有鴨子的事兒。
咦?谷歌AI反水了?
為了搞清楚這件事,供職於BuzzFeed的數據科學家Max Woolf設計了一個更複雜的實驗,他乾脆讓這張圖旋轉起來,倒是要看看,谷歌AI什麼表現。
就是這麼一轉,成了推特上的熱門。
咱們以鴨子嘴(兔子耳朵)為參考,說下這個實驗的結果。過程如下所示。紅色代表兔子,藍色代表鴨子。
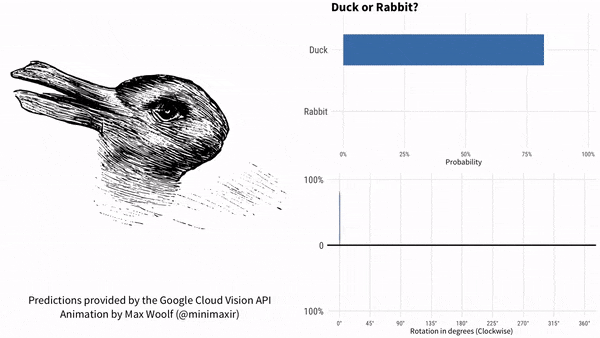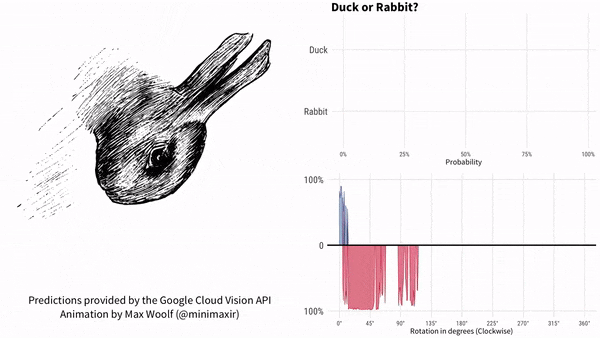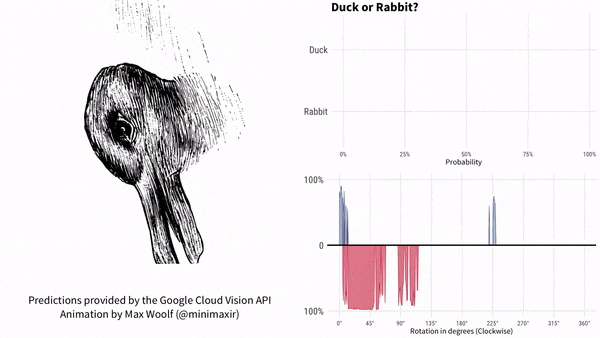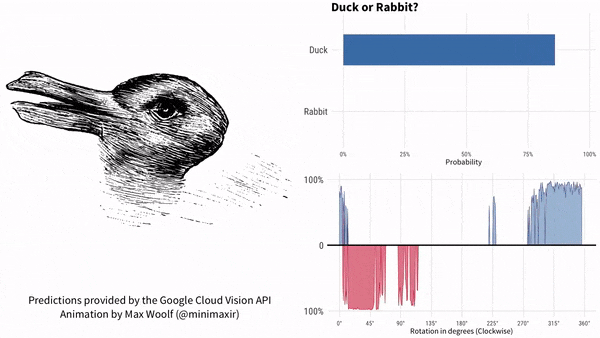
圖片順時針旋轉。谷歌AI最初認為是鴨子,鴨子嘴指向9點方向。隨着鴨子嘴向上轉到10點方向,很快谷歌AI就認為畫裏面是兔子了,直到鴨子嘴轉到2點方向之後。此後一段時間,谷歌AI認為既不是鴨子也不是兔子。一直到7點方向,谷歌AI再次肯定是一隻鴨子。
有人說此刻谷歌AI的內心,可能就像動畫兔八哥里的這個場景。

還有人給了更多類似的挑戰圖片,想考驗一下谷歌AI的水平。
比如這種:
以及這種:
等等等等……據說能看出來鴨子,又能看出來兔子,說明一個人的想像力更好。
大家如果有興趣,可以自己去嘗試。
這裏用到的谷歌AI,實際上是谷歌的Cloud Vision。這個服務提供了預訓練的機器學習模型,可以用來理解圖片內容。地址在此:
https://cloud.google.com/vision/
頁面上提供了Try the API,直接傳圖就行~
鴨兔幻覺
「鴨兔同圖」問題讓不少網友犯了難,這是一個比「雞兔同籠」更玄幻更有意思的問題。還有一大波人類,正常嘗試判斷AI的心理狀態……
網友sangnoir認為,糾結圖中到底是什麼完全沒有意義,圖像本身中既包含了兔子又包含了鴨子,人類尚且覺得兩者都在,何必非得讓AI去做「二選一」的定性呢?
下面這個數字大家都認識,但是旋轉起來,到底是幾呢?

△若旋轉起來,圖片是「6」還是「9」?
談到旋轉,更進一步,之前有個「旋轉舞者」的問題更困難,下面這個小人到底是順時針還是逆時針旋轉,人類的看法也兵分兩路↓↓↓

實際上,當你視線以從左往右的方向掃過這張圖時,你看到的是逆時針轉圈,反之,當你先看到的是右邊時,你眼中的她是順時針的。在計算機視覺上,還有一個專門的名詞解釋這個現象,即多穩態/雙穩態感知。
也有網友表示,這件事恰恰反映了AI識別物體的能力已經高於人類了。
他認為,之所以Google Cloud Vision會連續給出不同答案,是因為AI系統每隔一段時間就會基於旋轉的圖像重新判斷並實時更新。
而人類的大腦往往就卡在第一印象了,所以才會咬定一個物種不放鬆。
也有人表示,這件事也啟發了視覺從業者反思AI識別物體時的方向問題。
比如網友Sharlin就認為,人類在判斷物體時對於空間的認識具有先驗性,用這樣的標註數據訓練出的模型,在不知不覺中也將空間和方向等因素考慮在內了。
但是,現在大多數視覺算法都想努力實現某種程度的旋轉不變性,還提出了「尺度不變特徵轉化(SIFT)」等概念。「不變性」可能也反映了人類的局限性,輸入方向也是一個重要考慮因素。
膠囊網絡或許可行
同一張圖片,由於位置不同,AI就產生了不同的判斷。也有很多人想到了更多。
傳統的卷積神經網絡CNN架構中有個弊端,就是缺乏可用的空間信息。
一般來說,CNN提取、學習圖像特徵來識別物體。拿面部識別任務來說,底層網絡學習一般性特徵(比如面部輪廓等),隨着層數的加深,提取的特徵就越複雜,特徵也精細到眼睛、鼻子等器官。
問題來了,神經網絡用它學習到的所有特徵作出最後的輸出,但唯獨沒有考慮到可用的空間信息。人類可以識別出下面這張有些錯位的人臉,但CNN就不能。
其實,讓神經網絡自己學會判斷空間的研究已經有了。2017年,「深度學習」三巨頭之一的AI大牛Geoffrey Hitton就提出了一種「膠囊網絡」(Capsule Networks)的概念。
膠囊網絡的解決辦法是,實現對空間信息進行編碼,也就是計算物體的存在概率。這可以用向量來表示,向量的模代表特徵存在的概率,向量方向表示特徵姿態信息。
在論文Dynamic Routing Between Capsules中,Hinton和谷歌大腦的同事Sara Sabour、Nicholas Frosst詳細解釋了「膠囊網絡」的詳細情況。
Hinton等人表示,人類視覺系統中,有一個「注視點」的概念,能讓人類在視野範圍內只對極小部分的圖像進行高解像度處理。
這篇論文假設一個注視點帶給我們的信息不僅僅是一個識別對象及其屬性,還假設我們的多層視覺系統在每個注視點上都創建了一個類似分析樹的東西,並忽略這些分析樹在多個注視點之間如何協調。
分析樹通常靠動態分配內存來構建,但是這篇論文假設對於單個注視點來說,分析樹是從固定多層神經網絡中「雕刻」出來的,就像用石頭刻出雕像一樣。
神經網絡的每一層會被分成很多組神經元,每一組稱為一個capsule,而分析樹的每個節點對應着一個活躍的「膠囊」。
膠囊是輸出是一個向量,這篇論文中,在保持它方向不變的情況下應用非線性縮小了它的量級,確保這個非線性輸出不大於1。
也正因為膠囊的輸出是一個向量,確保了能使用強大的動態路由機制,來確保這個輸出能夠發送到上層合適的parent處。
膠囊網絡現在的研究階段,就像本世紀初將RNN應用於語音識別的階段。有非常具有代表性的理由相信這是一個更好的方法,但很多細節還需要接續觀察。
















{kind=link}