一個小小字符「0」,竟引得B站全面崩潰。

不知你是否還記得那一夜,B站「大樓停電」、「伺服器爆炸」、「程式設計師刪庫跑路」的徹夜狂歡。(手動狗頭)
時隔一年,背後「真兇」現在終於被阿B披露出來——
沒想到吧,就是這麼簡單幾行代碼,直接干趴B站兩三個小時,搞得B站程式設計師徹夜無眠頭髮狂掉。
你可能會問,這不就是個普普通通用來求最大公約數的函數嗎,怎麼就有如此大的威力?
背後一樁樁一件件,歸根結底其實就一句話:0,它真的不興除啊。

具體詳情,咱們還是一起來看看「事故報告」。
字符串「0」引發的「血案」
先來說道說道引發慘案的根本原因,也就是開頭貼出的這個gcd函數。
學過一點編程知識的小夥伴應該都知道,這是一種用輾轉相除法來計算最大公約數的遞歸函數。
跟我們手算最大公約數的方法不同,這個算法是醬嬸的:
舉個簡單的例子,a=24,b=18,求a和b的最大公約數;
a除以b,得到的餘數是6,那麼就讓a=18,b=6,然後接着往下算;
18除以6,這回餘數是0,那麼6也就是24和18的最大公約數了。
也就是說,a和b反覆相除取餘數,直到b=0,函數中:
if b==0 then return a end
這個判斷語句生效,結果就算出來了。
基於這樣的數學原理,我們再來看這段代碼,似乎沒什麼問題:
但如果輸入的b是個字符串「0」呢?
B站的技術解析文章中提到,這段出事的代碼是用Lua寫的。Lua具有這麼幾個特點:
這是一種動態類型語言,常用習慣里變量不需要定義類型,直接給變量賦值就行。Lua在對一個數字字符串進行算術操作時,會嘗試將這個數字字符串轉成一個數字。在Lua語言中,數學運算n%0的結果是nan(Not A Number)。
我們來模擬一下這個過程:
1、當b是一個字符串「0」時,由於這個gcd函數沒有對其進行類型校驗,因此在碰上判定語句時,「0」不等於0,代碼中「return_gcd(b, a%b)」觸發,返回_gcd(「0」, nan)。
2、_gcd(「0」, nan)再次被執行,於是返回值變成了_gcd(nan, nan)。
這下就完犢子了,判定語句中b=0的條件永遠沒法達到,於是,死循環出現了。
也就是說,這個程序開始瘋狂地原地轉圈,並且為了一個永遠得不到的結果,把CPU佔了個100%,別的用戶請求自然就處理不了了。

那麼問題來了,這個「0」它到底是怎麼進去的呢?
官方說法是:
在某種發佈模式中,應用的實例權重會短暫地調整為0,此時註冊中心返回給SLB(負載均衡)的權重是字符串類型的「0」。此發佈環境只有生產環境會用到,同時使用的頻率極低,在SLB前期灰度過程中未觸發此問題。
SLB在balance_by_lua階段,會將共享內存中保存的服務IP、Port、Weight作為參數傳給lua-resty-balancer模塊用於選擇upstream server,在節點weight=「0」時,balancer模塊中的_gcd函數收到的入參b可能為「0」。
bug是如何定位的
以「事後諸葛亮」的視角來看,這個引發B站全面崩潰的根本原因多少有點讓人直呼「就這」。
但從當事程式設計師的視角來看,事情確實沒有辣麼簡單。
當天晚上22:52分——大部分程式設計師才剛下班或者還沒下班的節骨眼(doge),B站運維收到服務不可用的報警,第一時間懷疑機房、網絡、四層LB、七層SLB等基礎設施出現問題。
然後立馬和相關技術人員拉了個緊急語音會議開始處理。
5分鐘後,運維發現承載全部在線業務的主機房七層SLB的CPU佔用率達到了100%,無法處理用戶請求,排除其他設施後,鎖定故障為該層。
(七層SLB是指基於URL等應用層信息的負載均衡。負載均衡通過算法把客戶請求分配到伺服器集群,從而減少伺服器壓力。)
萬般緊急之時,小插曲還現了:遠程在家的程式設計師登上VPN卻沒法進入內網,只好又去call了一遍內網負責人,走了個綠色通道才全部上線(因為其中一個域名是由故障的SLB代理的)。
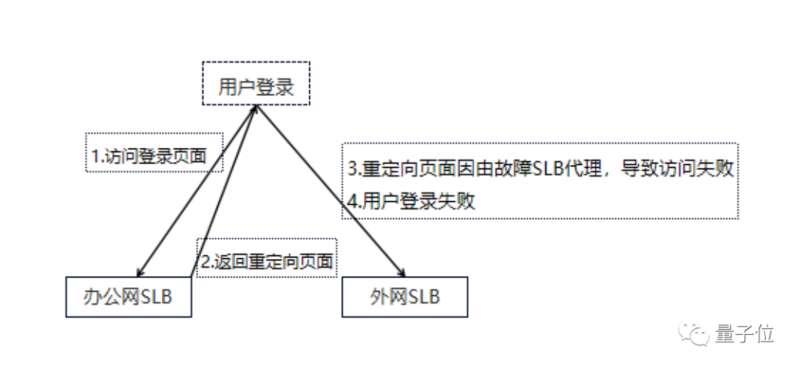
此時已經過去了25分鐘,搶修正式開始。
首先,運維先熱重啟了一遍SLB,未恢復;然後嘗試拒絕用戶流量冷重啟SLB,CPU依然100%,還是未恢復。
接着,運維發現多活機房SLB請求大量超時,但CPU未過載,正準備重啟多活機房SLB時,內部群反應主站服務已恢復,視頻播放、推薦、評論、動態等功能已基本正常。
此時是23點23分,距離事故發生31分鐘。
值得一提的是,這些功能恢復其實是事發之時被網友們吐槽的「高可用容災架構」發揮了作用。
至於這道防線為啥一開始沒發揮作用,裏頭可能還有你我一點鍋。
簡單來說,就是大傢伙點不開B站就開始瘋狂刷新,CDN流量回源重試+用戶重試,直接讓B站流量突增4倍以上,連接數突增100倍到千萬級別,多活SLB就給整過載了。

不過,並不是所有服務都搞了多活架構,至此事情並沒完全解決。
接下來的半個小時裏,大家做了很多操作,回滾了最近兩周左右上線的Lua代碼,都沒把剩餘的服務恢復。
時間來到了12點,沒有辦法了,「先不管bug是怎麼出來的,把服務全恢復了再說」。
簡單+粗暴:運維直接耗時一小時重建了一組全新的SLB集群。
凌晨1點,新集群終於建好:
一邊,有人負責陸續將直播、電商、漫畫、支付等核心業務流量切換到新集群,恢復全部服務(凌晨1點50分全部搞定,暫時結束了崩了逼近3個小時的事故);
另一邊,繼續分析bug原因。
在他們用分析工具跑出一份詳細的火焰圖數據後,那個搞事的「0」才終於露出了一點端倪:
CPU熱點明顯集中在一個對lua-resty-balancer模塊的調用中。而該模塊的_gcd函數在某次執行後返回了一個預期外的值:NaN。
同時,他們也發現了觸發誘因的條件:某個容器IP的weight=0。
他們懷疑是該函數觸發了jit編譯器的某個bug,運行出錯陷入死循環導致SLB CPU100%。
於是就全局關閉了jit編譯,暫時規避了風險。一切都解決完後,已經快4點,大家終於暫時睡了個好覺。
第二天大家也沒閒着,馬不停蹄地在線下環境復現了bug後,發現並不是jit編譯器的問題,而是服務的某種特殊發佈模式會出現容器實例權重為0的情況,而這個0是個字符串形式。
正如前面所說,這個字符串「0」在動態語言Lua中的算術操作中,被轉成了數字,走到了不該走的分支,造成了死循環,引發了b站此次前所未見的大崩潰事件。
遞歸的鍋還是弱類型語言的鍋?
不少網友都還對這次事故記憶猶新,有回想起自己就是以為手機不行換電腦也不行的,也有人還記得當時5分鐘後此事就上了熱搜。
大家都很詫異,就這麼一個簡單的死循環就能造成如此大的網站崩服。
不過,有人指出,死循環不罕見,罕見的是在SLB層、在分發過程出問題,它還不像在後台出問題很快能重啟解決。
為了避免這種情況發生,有人認為要慎用遞歸,硬要用還是設置一個計數器,達到一個業務不太可能達到的值後直接return掉。
還有人認為這不怪遞歸,主要還是弱類型語言的鍋。
以此還導致了「詭計多端的『0』」這一打趣的說法。

另外,由於事故實在是耽誤了太久、太多事兒,當時B站給所有用戶補了一天大會員。
有人就在此算了一筆賬,稱就是這7行代碼,讓b站老闆一下虧了大約1,5750,0000元。(手動狗頭)

對於這個bug,你有什麼想吐槽的?



















{kind=link}